『分享预告』在线数据迁移实践,如何为飞行中的飞机换引擎
-
主题:在线数据迁移实践,如何为飞行中的飞机换引擎
时间:12 月 22 日 20:00 —— 21:30
地点:QingCloud 技术分享群,文末有二维码。
讲师:

李明隆 青云QingCloud 软件工程师本期内容介绍:
云平台的逐渐成熟与完善,越来越多的开发者和企业选择将应用程序迁移到云上。对于企业来说,企业上云最大的难点就是数据迁移,必须保证自身的业务在整个迁移过程中正常运行,服务不受影响。很多人将其比喻成“飞行过程中换发动机”“给行驶的汽车换轮胎”,但实际上并没有那么困难。
今天我将会从一个具体案例的角度来和大家聊聊如何将数据进行在线迁移,同时,企业的业务不受任何影响。
本次分享的课程大纲如下:
企业对于数据迁移的需求
传统数据迁移的痛点
迁移工具介绍
迁移方案以及具体实践PS:提问即可获得青云QingCloud T恤一件。


-
在线数据迁移实践,如何为飞行中的飞机换引擎
随着云平台的逐渐成熟与完善,越来越多的开发者和企业选择将业务迁移至云平台上。而对于企业来说,上云最大的痛点之一就是数据的迁移,其必须尽可能得保证自身的业务在整个迁移过程中正常运行,服务不受影响。很多人将其比喻成“飞行过程中换发动机”“给行驶的汽车换轮胎”,但实际上并没有那么困难。
今天我将会从一个具体案例的角度来和大家聊聊如何将数据进行迁移,同时企业的业务不受任何影响。
企业 A 面临的问题
首先我们从一个真实的用户场景谈起:
企业 A 有一个社交 App,允许用户上传、下载图片及视频,视频和图片的 Size 都比较小,其数据都放在本地服务器。
随着应用的上线以及用户的不断推荐,企业 A 的 App 用户超过了百万,此时企业 A 必须要解决数据存储容量、数据安全、高可靠、可存储文件数量、读写性能等诸多问题,以保证用户体验。
考虑数据中包含大量与用户相关的非结构化数据,使用本地文件系统来存储非结构化数据的方法通常会带来可扩展性以及性能上的问题,比如说消耗大量的 CPU 、存取性能太差等。
在大量公有云用户多样化的应用场景中, QingStor™ 对象存储在性能(高并发)、可用性、稳定性等方面得到了充分的验证。所以企业 A 选择将数据存放在容量无限且性能优秀的存储系统 ——青云 QingCloud 提供的 QingStor™ 对象存储。
接下来,让我们看看企业 A 的数据是如何迁移到 QingStor™ 对象存储上的。
传统数据迁移的痛点传统数据迁移会将原有存储服务器的上传通道关闭,然后将原有数据迁移到新的存储服务器。
在所有数据迁移完毕之后,再打开数据上传通道,将上传通道改为新的存储服务器,整个过程无疑会影响用户的业务。而且因为用户客户端更新的滞后,上传通道可能仍然为原有存储服务器。
针对传统数据迁移的痛点,QingStor™ 推出了无缝数据迁移方案,此方案提供两种迁移方式:
-
被动触发迁移
-
用户主动迁移
综合运用两种迁移方式,可以在不中断业务的前提下,平滑完整地进行迁移。
迁移工具及服务介绍
被动触发迁移 - 外部镜像
用户可以为 Bucket 设置外部镜像源站,当请求的对象在 Bucket 中不存在时,服务端把对象名称拼接在外部镜像源站后作为抓取的源链接,然后自动从源站抓取(回源),并写入到 Bucket 当中。
在回源过程中,请求这个对象的客户端,有可能会下载到源站文件,也有可能收到重定向到源站相应路径的 302 请求。
在回源完成后,客户端能够直接从 Bucket 中获取这个对象。
假设企业 A 的外部镜像源站为 http://img.expamle.com
企业 A 在QingStor™ 的 Bucket 的默认域名为 http://bucketname.pek3a.qingstor.com。
下面结合示意图,说明一下外部镜像的工作原理:
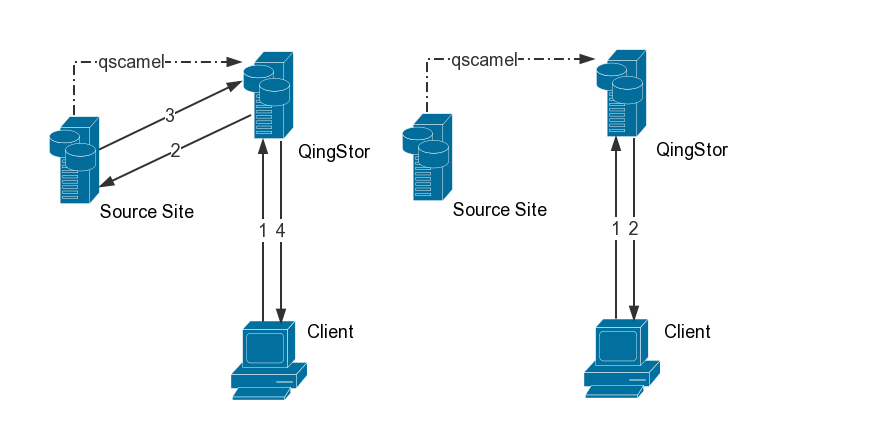
图中虚线部分的qscamel 为 主动迁移命令工具 (后面会讲),实线部分为被动触发的外部镜像流程。
示意图左侧为首次请求:
- 用户发起获取对象的请求,如 http://bucketname.pek3a.qingstor.com/blog.png
- 对象在 QingStor™ Bucket 中不存在,且已经为 Bucket 设置了外部镜像源站,服务端把对象名称 blog.png 拼接到源站,生成源链接http:/img.example.com/blog.png
- QingStor™ 服务端从该源链接抓取。
- 在抓取过程中,请求这个对象的客户端,有可能会下载到源站文件,也有可能收到重定向到源站相应路径的 302 请求。
示意图右侧为抓取完成后,再次发起请求:
-
用户发起获取对象的请求
-
对象在QingStor™ Bucket 中已存在,直接返回。
用户主动迁移 - Fetch API
如果需要迁移单个源站资源,可以使用 “PUT Object - Fetch” API,见 API 文档: https://docs.qingcloud.com/qingstor/api/object/fetch.html
该接口在请求中附带源链接。QingStor™ 会从该链接抓取资源,保存到指定的对象中。
用户主动迁移 - qscamel
命令行工具 qscamel 是 API “PUT Object - Fetch” 的高级封装。既支持从指定的文件中读取源站列表,也支持直接指定其他对象存储平台,进行批量迁移。
qscamel有如下特点:
-
支持并行迁移,即同时迁移多个对象。
-
支持给迁移任务命名,用来继续迁移未完成的迁移任务。 qscamel 会记录本次迁移任务中成功迁移的源站。在退出后、重新执行时,qscamel 会跳过已经成功迁移的源站资源,迁移剩下未完成的源站资源。
3.支持灵活的覆盖模式。qscamel 默认进行增量迁移,即比较源站资源和 QingStor™ Bucket 中对象的最后更新时间。迁移 Bucket 中已存在但未更新的对象,和 Bucket 中不存在的对象。除了增量迁移之外,还可以设置为不覆盖已存在的对象和强制覆盖。
4.支持指定日志文件。qscamel 的默认输出到 stdout,可以指定输出到日志文件。
更多详细介绍请参考相关文档:
外部镜像文档: QingStor Bucket External Mirror
fetch接口文档: QingStor PUT Object - Fetch
qscamel文档: QingStor qscamel
qscamel 项目地址: github.com/yunify/qscamel迁移方案以及具体实践
下面是迁移方案推荐步骤:
-
通过命令行工具 qscamel 将冷数据批量上传到 QingStor™。
-
更改数据上传路径,将路径设置为 QingStor™ Bucket 默认域名,或者绑定自定义域名。
-
用户客户端(如 ios,android,pc)更新滞后,部分客户端没有更新到新版,导致数据仍然上传到了源站,不在 QingStor™ Bucket 中。通过设置外部镜像源站,在访问对象时被动触发回源可以解决此问题。当用户客户端更新完毕,外部镜像回源流量基本为0时,外部镜像功能已经完成使命。
-
由于外部镜像功能是被动触发的,源站中可能还存在没有迁移的数据。此时使用命令行工具 qscamel 进行增量迁移。
下面给出外部镜像的使用示例:
- 设置外部镜像源站: 在 Bucket 页面点击设置 -> 外部镜像 -> 填写源站点.示例源站是豆瓣的图片服务器 https://img1.doubanio.com。
.png)
- 示例 Bucket 的默认域名是 http://migrate-target-bucket.pek3a.qingstor.com。在浏览器内访问http://migrate-target-bucket.pek3a.qingstor.com/lpic/s29166331.jpg,QingStor 将从 https://img1.doubanio.com/lpic/s29166331.jpg 抓取 。
.png)
从下面的图片可以看出,此次回源客户端可以直接下载源站文件。
.png)
- 在回源完毕后,可以在 Bucket 文件列表看到该对象。
.png)
下面给出一些 qscamel 的运行示例:场景一:数据存储在本地服务器
由于数据存储在本地服务器,企业 A 可以将资源链接列在源站列表文件中,每行源站以 ‘\n’ 结束。然后通过 -t file -s <source-list-file> 指定源站列表文件进行迁移。
(1) 读取源站列表文件,进行批量迁移
.png)
(2) 退出后、重新执行时,根据记录文件,跳过成功迁移的源链接。示例跳过了成功迁移的两条源链接,只迁移 https://img3.doubanio.com/lpic/s29154751.jpg
.png)
(3) 下面演示 -i --ignore-existing 跳过迁移 Bucket 中已经存在的对象,和-n --dry-run可以看到 Bucket 中已经有3个对象。
.png)
源站列表文件中,共有四个源链接。其中前三个在 Bucket 中已存在,使用 -i --ignore-exising 选项时跳过了这三个。
使用 -n --dry-run 选项时,qscamel 会尝试运行,并输出运行结果,但不做实际迁移。
.png)
场景二:数据存储在其他云平台
从其他对象存储平台迁移,通过 -t <platform> -s <source-bucket-name> 指定对象存储平台和将要迁移的 Bucket 名称。(除此之外,还需要指定其他平台的认证信息)
(1) 指定亚马逊 S3 的 Bucket,进行批量迁移
.png)
.png)
(2) 指定七牛云的 Bucket,进行批量迁移
.png)
.png)
(3) 指定阿里云的 Bucket,进行批量迁移
.png)
.png)
-
-
占楼,本楼用于问题收集以及奖品发放。
1、如果数据量巨大,走公网太慢了,有什么解决方案么?@yhuos
2、如何处理迁移过程中业务上的新增数据?@TakeTry
3、数据迁移开始后,开发者都需要随时验证数据迁移成功完成与否,这个有什么工具可以随时展示么?类似于报表之类的?@yuandan525
4、有用到纠错码么?@shuo-cui
5、如果我的数据都在云主机上,如何最方便地迁移到对象存储上去?@leaneger
6、如果从kvm迁移到云平台,通过复制img到云平台还是导入数据比较容易实现?@wqzte
7、迁移的回退有没有好的方案,特别是运行了一段时间之后的情况?@nnnavy
-
我是来拿奖品的~~~~
-
@muge0913 哈哈,需要提问题哦。
-
听完后提,:) 能占座么先~~
-
@muge0913 可以啊。。。。
-
如果从kvm迁移到云平台,通过复制img到云平台还是导入数据比较容易实现
-
迁移的回退有没有好的方案,特别是运行了一段时间之后的情况



