Schemaless:Uber基于MySQL的可扩展数据库(一)
-
Mezzanine项目描述了我们如何从单独的Postgres实例中将Uber的核心trip数据提取出来,就成了Schemaless这个具备容错性和高可用性的数据库。本文进一步描述了Schemaless的架构,及其在Uber基础结构中的详细角色,以及它如何成为这样的角色。
我们关于新数据库的努力
2014年初,由于业务增长迅猛,我们的数据库空间终告耗尽。随着扩张,每次新入驻城市,每次里程增长形成里程碑都将我们推向险境,直到我们发现,到年末Uber的基础架构将无法继续发挥功用:Postgres没办法再存储trip数据了。我们的使命是实现Uber的下一代数据库,这个任务花了数月时间,将近快一年,全世界有多个办公室的多名工程师参与了这项任务。
不过首先,在大量商用与开源可选方案存在的情况下,为什么还要自己打造一个可扩展数据库呢?对于新trip数据库,我们有五个关键的要求:
- 新的解决方案要有能力通过增加服务器而线性地增加容量,这是原有的Postgres所缺乏的。增加服务器不但要增加可用的硬盘容量,还要减少系统的响应时间。
- 需要写入能力。之前我们曾用Redis实现了一个简单的缓存机制,因此如果写入Postgres的做法失败的话,可以稍后再重试,因为trip在Redis中有缓存备份。不过用Redis时,trip无法从Postgres中读取,没有类似计费之类的功能。很烦人,不过至少数据没丢。随着时间推移,Uber成长起来,我们基于Redis的解决方案无法扩展。Schemaless必须支持类似Redis的机制,不过最好包含写入功能。
- 需要通知下游依赖关系的方式。在现有系统中,我们同时处理多个trip组件,比如计费、分析等。这个过程很容易出错:如果某一步出错,必须整个重来,即便有些组件已经成功处理。这将无法扩展,因此我们想要将这些步骤拆分成独立的步骤,由数据变更启动。我们确实有一个异步的trip事件系统,不过是基于Kafka 0.7的。由于不能无损运行,我们需要一个新系统,其中某些是类似的,但却可以无损运行。
- 需要二级索引。由于要从Postgres迁移过去,新的存储系统必须支持Postgres索引,也就是说在搜索trip时使用二级索引。
- 系统运营需要有可靠度,因为其中包含了trip数据的关键任务。如果凌晨3点我们收到叫车需求,而数据库无法响应查询并挂起业务,我们是否有相关的操作知识能快速修复问题呢?
鉴于以上因素,我们分析了常用可选系统(Cassandra、Riak、MongoDB等等)的优势与潜在的局限性。为了说明,下面将列出不同系统的功能差异:

这三个系统都能通过在线增加新节点,而执行线性扩展;其中二个可以在故障时接受写入命令;三个系统均缺少内置的下游依赖通知机制,需要借助应用层面实现;三者都包含索引功能,但如果针对不同的值进行索引,查询会很缓慢,因此使用了scatter-gather方式来查询所有节点;我们用过的一些系统是单集群的,不提供面向用户的在线流量,并在连接服务时有各种各样的运营问题。
最终,我们决定着重考虑运营可靠度的问题,因为里面会包含trip数据的关键任务。可选方案理论上也许是可靠的,但我们是否掌握相关知识,能否立即发挥其最大功效,在很大程度上决定了我们开发自己的解决方案。不仅根据我们所使用的技术,还因为我们在团队中的经验。
应当注意,我们针对这些系统的调研持续了2年多,其中并没有适用于trip存储用例的。现在,在我们基础架构的其他部分采用了Cassandra和Riak,并在生产环境中服务于数百万用户。
在Schemaless中我们相信
在我们的时间表中,上述选项中没有一个能满足我们的需要,于是我们决定自行构建一个尽可能便于运行,又吸取了别家扩展经验的系统。设计的灵感来源于Friendfeed,运营方面的侧重点受到Pinterest的启发。
最终我们构建了一个键值存储库,可以存放JSON数据而无需严格的模式验证,完全的无模式风格(点题)。有一个只扩展分片MySQL,在MySQL主服务器故障时支持缓存写入,并有一个数据变更通知的发布-订阅功能(命名为trigger)。最后,Schemaless支持数据的全球索引。下面我们对这个数据模型还有一些关键功能进行概述,包括一个trip的剖析,更深入的例子会放在后面的一篇文章中。
Schemaless数据模型
Schemaless是一个只扩展的稀疏三维哈希表持久化实现,非常类似谷歌的Bigtable。在其中最小的数据实体被称为cell,是不可变数据。一旦写入,无法被覆盖或删除。而cell是一个JSON blob,被row key和column name引用,引用值被称为ref key;row key是一个UUID,column name是一个字符串,ref key是一个整数。
可以将row key想象成关系数据库中的一个主键,将column name当作一个列。但在Schemaless中,没有预定义或执行模式,每行无需分享column name;事实上column name完全由应用所定义;ref key用来指定row key和column的cell版本。因此如果一个cell需要更新,可以用更高的ref key写入一个新cell,最新的cell就是ref key最高的那个。ref key也可以用在列表的条目中,不过通常用于标注版本。通过应用程序决定使用哪个架构。一般应用将相关数据按照列相同来分组,然后每列的所有cell应用端的架构基本相同。这种分组是很好的办法,可以将数据批量修改,并允许应用快速修改架构,而无需数据库停机。下面的实例阐述了更多相关内容。
实例:在Schemaless中的trip存储
在深入之前,我们看一下Uber中一个trip的剖析。Trip数据在不同的时间点生产,从上车下车到付费,这些不同的信息是异步的,伴随着旅客发送反馈,或者后台处理。下面的图标是一个简单的流程图,包含了一个Uber trip的不同部分:

这张图表展示了我们trip流程的简化版本。*代表这部分是可选的,可能已经出现多次。
一个trip由乘客发起,司机接受,包含开始与结束的时间戳。该信息包含了基本的trip,从中我们计算trip的花费(费用),也就是司机的收费。在trip结束后,我们可能得调整费用,与司机产生或借或贷的关系。可能会添加备注,从乘客或司机处发出反馈(在图表中以星号标注)。或者在第一个过期或支付失败后,可能需要尝试从多个信用卡中选择付款。这个流程是一个数据驱动的过程。随着有可用或新增数据,执行特定流程。信息中的某些,比如乘客或司机评价可以在trip结束后数天后进行。
因此,我们如何将上述trip模型映射到Schemaless中?
Trip数据模型
用斜体代表UUID,上标代表column name,下面的表格显示了一个trip简化版的数据模型。我们有2个trip(UUID分别是trip_uuid1和trip_uuid2),还有4个colume(BASE、STATUS、NOTES、FARE ADJUSTMENT)。一个cell用一个方框代表,包含数字和JSON blob(以 {…}缩写)。叠放的方框代表版本(即不同的ref key)。
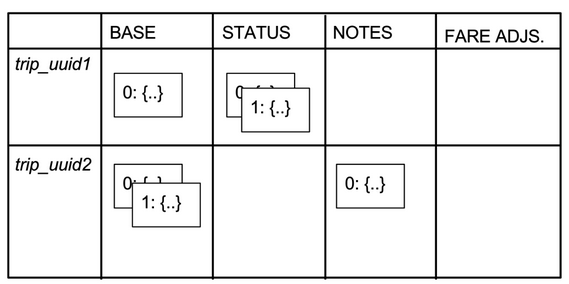
trip_uuid1有三个cell:BASE列有一个,STATUS列有2个,FARE ADJUSTMENT列为空。trip_uuid2在BASE列有2个cell,NOTES列有一个,FARE ADJUSTMENT也是为空。对于Schemaless来说,这些列没什么区别;因此每列语义由应用来定义,在本例中是Mezzanine服务。
在Mezzanine中,BASE列的cell包含基本的trip信息,比如司机的UUID,trip时间。STATUS列包含trip的当前支付状态,我们在其中为每次支付插入一个cell,来支付trip。如果信用卡金额不足或者过期,支付会失败。 NOTES列包含一个cell,方便司机记录任何与trip关联的备注,或者Uber的DOps(雇佣司机)来记录。最后,FARE ADJUSTMENT列包含的cell用在trip费用修改的时候。
我们用这列避免数据冲突,并将需要在更新中写入的数据数量尽可能减到最少。BASE列在trip结束后写入,这样一般只用一次。STATUS列在尝试支付时写入,即在BASE列写入后才写入,而且可以在支付失败时执行多次写入。某种情况下,NOTES列也可以执行多次写入,也发生在BASE列写入之后,不过与STATUS列写入是完全分离的。类似的,FARE ADJUSTMENT列在trip费用变更后只会写入一次。
Schemaless Trigger
Schemaless的关键功能在于trigger——可以在Schemaless实例变更时获得通知。由于cell是不可变的,新版本只能添加,每个cell也代表一次变更或一个版本,因此实例中的值可视为一个变更日志,针对指定的实例,可以监听这些变化,或针对它们触发功能,很像Kafka这样的事件总线系统。
Schemaless trigger让Schemaless成为一个完美的来源真实数据库,因为除了随机访问数据,下流依赖也可以通过trigger功能来监听并触发任何应用特定代码(类似LinkedIn’s DataBus系统)。
在其他用例中,Uber在BASE列写入Mezzanine实例时,使用Schemaless trigger来支付trip。针对上面的实例,一旦trip_uuid1的BASE列有数据写入,我们的支付服务触发BASE列找到这个cell,尝试通过信用卡支付trip。支付结果无论是成功还是失败,都会返回Mezzanine,写入STATUS列。这种计费方式与trip创建相分离,而Schemaless扮演了异步事件总线。

轻松访问索引
最后,Schemaless支持在JSON blob字段的索引定义。通过这些预定义字段执行索引查询,找到匹配查询参数的cell。这种索引查询非常高效,因为只需访问单个片区,找到要返回的cell组。事实上,查询可以进一步优化,因为在Schemaless中,索引可直接使用非规范化的cell数据。在索引查询中,非规范化数据代表着只需查询一个片区,便可查询并取回信息。事实上,我们通常推荐Schemaless用户在可能需要用到索引的部分中都使用非规范化数据,以防需要直接用row key查询并取回cell。在某种意义上,这样一来我们用存储交换来了快速查询的性能。
举个Mezzanine的例子,我们通过定义的二级索引可以找到指定的司机trip。我们将trip的创建时间与城市作为非规范化数据。这样就能按照指定的时间范围,找到某个城市中某个司机所有trip。下面我们用YAML格式定义driver_partner_index,作为trip数据库的一部分,定义在BASE列(实例中有注解)。
table: driver_partner_index # Name of the index. datastore: trips # Name of the associated datastore column_defs: – column_key: BASE # From which column to fetch from. fields: # The fields in the cell to denormalize – { field: driver_partner_uuid, type: UUID} – { field: city_uuid, type: UUID} – { field: trip_created_at, type: datetime}使用这个索引,通过筛选city_uuid或者trip_created_at,我们能够找出指定driver_partner_uuid的trip。在实例中,我们只用了BASE列的字段,不过Schemaless支持多个列的非规范化数据,相当于上面column_def列表中的多个条目。
就像刚才提到的,基于分片字段通过分片索引,Schemaless的索引可以达到很高的效率。因此对索引的唯一需求就是,索引中其中一个字段指定为一个分片字段(在上面的实例中是driver_partner_uuid)。这个分片字段确定了分片索引条目应当写入或取回。原因是,我们需要在查询索引时提供分片字段。也就是说在查询时,我们只需查询一个分片,就能取回索引条目。要注意:分片字段应当有一定的分布率。UUID最好,城市id次优,状态字段(enums)不好。
除此之外,Schemaless还支持equality/non-equality filtering和范围查询,并支持在索引中选择字段的子集,为索引条目指向的row key检索特定或所有的列。目前,分片字段必须是不可变的,因此Schemaless只需与一个片区对话。不过我们正在探索方法,找出如何在没有太大性能开销的情况下,让它成为可变的。
索引最终都是一致的;无论何时写入cell,都需要更新索引条目,不过不会在同一个事务中进行。一般来说,cell和索引条目不属于同一个片区。因此,如果我们打算给出一致的索引,就需要在写入时引入2PC,会带来很大的开销。最终,在索引一致且避免开销的情况下,Schemaless用户可能会在索引中看到旧数据。大多时候,cell变更与相应索引变更之间的延迟远远不到20毫秒。
总结
我们概述了数据模型、触发器和索引,这些都是定义Schemaless的关键功能,也是我们trip数据库引擎的主要组件。在后面的文章里,我们会看些Schemaless的其他功能,证明在Uber架构中这是一个多受欢迎的系统:更多内容将在架构上,作为存储节点的MySQL使用上,还有我们如何让客户端的触发容错上。
