Kudu: New Apache Hadoop Storage for Fast Analytics on Fast Data
-
Kudu: New Apache Hadoop Storage for Fast Analytics on Fast Data
This new open source complement to HDFS and Apache HBase is designed to fill gaps in Hadoop’s storage layer that have given rise to stitched-together, hybrid architectures.
The set of data storage and processing technologies that define the Apache Hadoop ecosystem are expansive and ever-improving, covering a very diverse set of customer use cases used in mission-critical enterprise applications. At Cloudera, we’re constantly pushing the boundaries of what’s possible with Hadoop—making it faster, easier to work with, and more secure.
In late 2012, we began a long-term planning exercise to analyze gaps in the Apache Hadoop storage layer that were complicating or, in some cases, preventing Hadoop adoption for certain use cases. In the course of this evaluation, we noticed several important trends and ultimately decided that there was a need for new storage technology that would complement the capabilities of what HDFS and Apache HBase provide. Today, we are excited to announce Kudu, a new addition to the open source Hadoop ecosystem. Kudu aims to provide fast analytical and real-time capabilities, efficient utilization of modern CPU and I/O resources, the ability to do updates in place, and a simple and evolvable data model.
In the remainder of this post we’ll offer an overview of our motivations for building Kudu, a brief explanation of its architecture, and outline our plan for growing a vibrant open source community in preparation for an eventual proposed donation to the ASF Incubator.

Gap in Capabilities
Within many Cloudera customers’ environments, we’ve observed the emergence of “hybrid architectures” where several Hadoop tools are deployed simultaneously. Tools like HBase are fantastic at ingesting data, serving small queries extremely quickly, and allowing data to be updated in place. HDFS, in combination with tools like Impala that can process columnar file formats like Apache Parquet, provides extreme performance for analytic queries on extremely large datasets.
However, when a use case requires the simultaneous availability of capabilities that cannot all be provided by a single tool, customers are forced to build hybrid architectures that stitch multiple tools together. Customers often choose to ingest and update data in one storage system, but later reorganize this data to optimize for an analytical reporting use-case served from another.
Our customers have been successfully deploying and maintaining these hybrid architectures, but we believe that they shouldn’t need to accept their inherent complexity. A storage system purpose built to provide great performance across a broad range of workloads provides a more elegant solution to the problems that hybrid architectures aim to solve.

A complex hybrid architecture designed to cover gaps in storage system capabilitiesNew Hardware
Another trend we’ve observed at customer sites is the gradual deployment of more capable hardware. First, we saw a steady growth in the amount of RAM that our customers are deploying, from 32GB per node in 2012 to 128GB or 256GB today. Additionally, it’s increasingly common for commodity nodes to include some amount of SSD storage. HBase, HDFS, and other Hadoop tools are being adapted to take advantage of this changing hardware landscape, but these tools were architected in a context where the most common bottleneck to overall system performance was the speed of the disks underlying the Hadoop cluster. Choices optimal for a spinning-disk storage architecture are not necessarily optimal for more modern architectures where large amounts of data can be cached in memory, and where random access times on persistent storage can be more than 100x faster.
Additionally, with a faster storage layer, the bottleneck to overall system performance is often no longer the storage layer itself. Generally, the next bottleneck that we see is CPU performance. With a slower storage layer, inefficiency in CPU utilization is often hidden beneath the storage bottleneck, but as the storage layer gets faster, CPU efficiency becomes much more critical.
We believe that there’s room for a new Hadoop storage system that is designed from the ground up to work with these modern hardware configurations and that emphasize CPU efficiency.
Introducing Kudu
To address these trends we investigated two separate approaches: incremental modifications to existing Hadoop tools, or building something entirely new. The design goals that we aimed to address were:
- Strong performance for both scan and random access to help customers simplify complex hybrid architectures
- High CPU efficiency in order to maximize the return on investment that our customers are making in modern processors
- High IO efficiency in order to leverage modern persistent storage
- The ability to update data in place, to avoid extraneous processing and data movement
- The ability to support active-active replicated clusters that span multiple data centers in geographically distant locations
We prototyped strategies for achieving these goals within existing open source projects, but eventually came to the conclusion that large architectural changes were necessary to achieve our goals. These changes were extensive enough that building an entirely new data storage technology was necessary. We started development more than three years ago, and we are proud to share the result of our effort thus far: a new data storage technology that we call Kudu.
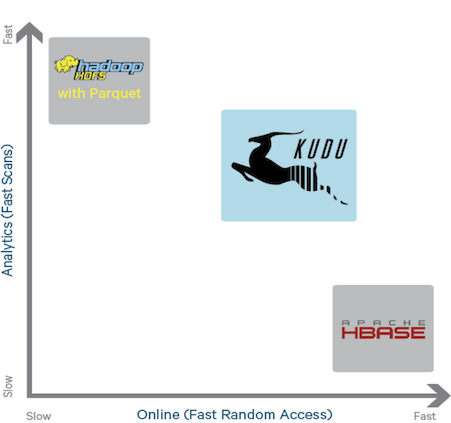
Kudu provides a combination of a characteristics for providing fast analytics on fast data.Kudu’s Basic Design
From a user perspective, Kudu is a storage system for tables of structured data. Tables have a well-defined schema consisting of a predefined number of typed columns. Each table has a primary key composed of one or more of its columns. The primary key enforces a uniqueness constraint (no two rows can share the same key) and acts as an index for efficient updates and deletes.
Kudu tables are composed of a series of logical subsets of data, similar to partitions in relational database systems, called Tablets. Kudu provides data durability and protection against hardware failure by replicating these Tablets to multiple commodity hardware nodes using the Raft consensus algorithm. Tablets are typically tens of gigabytes, and an individual node typically holds 10-100 Tablets.
Kudu has a master process responsible for managing the metadata that describes the logical structure of the data stored in Tablet Servers (the catalog), acting as a coordinator when recovering from hardware failure, and keeping track of which tablet servers are responsible for hosting replicas of each Tablet. Multiple standby master servers can be defined to provide high availability. In Kudu, many responsibilities typically associated with master processes can be delineated to the Tablet Servers due to Kudu’s implementation of Raft consensus, and the architecture provides a path to partitioning the master’s duties across multiple machines in the future. We do not anticipate that Kudu’s master process will become the bottleneck to overall cluster performance and on tests on a 250-node cluster the server hosting the master process has been nowhere near saturation.
Data stored in Kudu is updateable through the use of a variation of log-structured storage in which updates, inserts, and deletes are temporarily buffered in memory before being merged into persistent columnar storage. Kudu protects against spikes in query latency generally associated with such architectures through constantly performing small maintenance operations such as compactions so that large maintenance operations are never necessary.
Kudu provides direct APIs, in both C++ and Java, that allow for point and batch retrieval of rows, writes, deletes, schema changes, and more. In addition, Kudu is designed to integrate with and improve existing Hadoop ecosystem tools. With Kudu’s beta release integrations with Impala, MapReduce, and Apache Spark are available. Over time we plan on making Kudu a supported storage option for most or all of the Hadoop ecosystem tools.
A much more thorough description of Kudu’s architecture can be found in the Kudu white paper.
The Kudu Community
Kudu already has an extensive set of capabilities, but there’s still work to be done and we’d appreciate your help. Kudu is fully open source software, licensed under the Apache Software License 2.0. Additionally, we intend to submit Kudu to the Apache Software Foundation as an Apache Incubator project to help foster its growth and facilitate its usage.
The binaries for Kudu (beta) are currently available and can be downloaded from here. We’ve also created several installation options to help you get Kudu up and running quickly so that you can try it out—outlined in our documentation posted here. Today we’re also making the full history of Kudu development available both in our github repository and in a public export of our issue tracking system. Going forward, Kudu development will be done completely transparently and publicly.
Several companies—including AtScale, Intel, Splice Machine, Xiaomi, Zoomdata, and more—have already provided substantial feedback and contributions to help make Kudu better, but this is just the beginning. We welcome any feedback or contributions from anyone that has an interest in the use cases that Kudu addresses.
Based on the above we’re confident you will agree that Kudu complements HDFS and HBase to address real needs across the Hadoop community. We look forward to working with the community to improve Kudu over time.
Resources for Getting Involved
Mailing list: kudu-user@googlegroups.com
Discussion forum: http://community.cloudera.com/t5/Beta-Releases/bd-p/Beta
Contributions: http://getkudu.io./contributing.html
JIRA: http://issues.cloudera.org/projects/KUDU
