深入浅出CoreOS(二):cloud-config和etcd
-
这是关于深入浅出CoreOS的第二篇文章。在我上一篇文章中,主要阐述了CoreOS与其他Linux系统之间的不同、CoreOS的自动更新机制、发布渠道和集群发现的原理等。这篇文章中,我主要介绍一下cloud-config和etcd,文章最后会谈一些常见的集群架构。
Cloud-Config
Cloud-Config允许用户以声明的方式自定义各种级别的系统项目,例如网络配置,用户账户,systemd units(这将在下一篇文章中叙述)。Cloud-Config起源于Ubuntu,但在CoreOS中做了一些简单的修改。
在每一个CoreOS集群的核心,都有CoreOS-Cloudinit,我们用cloud-config文件来做初始化配置操作,在系统启动或者运行时用于配置系统。
什么是Cloud-Config?
Cloud-config是用YAML格式编写,规定使用空格和换行来限制列表、关联数组和值。这是关键性的格式化配置,所以在cloud-config部署到一个节点之前,必须使用CoreOS提供的在线工具进行验证。一个cloud-config文件必须使用#cloud-config开头,后续可以跟一个或多个关键字组成的关联数组。
下面是一些经常用到的关键字:
- CoreOS: 处理CoreOS的一些比如更新策略、etcd2,、fleet、flannel、units等的细节
- write_files: 使用命令在本地文件系统定义一系列文件
- ssh-authorized-keys 添加可以验证核心用户的ssh公钥
下面是一个cloud-config的例子:
#cloud-config hostname: core-01 coreos: update: reboot-strategy: off etcd2: name: core-01 initial-advertise-peer-urls: http://127.0.0.1:2380 initial-cluster-token: core-01_etcd initial-cluster: core-01=http://127.0.0.1:2380 initial-cluster-state: new listen-peer-urls: http://0.0.0.0:2380,http://0.0.0.0:7001 listen-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001 advertise-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001 units: - name: etcd2.service command: start - name: fleet.service command: start - name: docker-tcp.socket command: start enable: true content: | [Unit] Description=Docker Socket for the API [Socket] ListenStream=2375 BindIPv6Only=both Service=docker.service [Install] WantedBy=sockets.target - name: docker.service command: start drop-ins: - name: 50-insecure-registry.conf content: | [Unit] [Service] Environment=DOCKER_OPTS='--insecure-registry="0.0.0.0/0"' write-files: - path: /etc/conf.d/nfs permissions: '0644' content: | OPTS_RPC_MOUNTD="" ssh_authorized_keys: - ssh-rsa 121313dqx1e123e12… user@my_mac想了解更过关于cloud-config的配置参数,请参考文档说明。
ETCD2.X
Etcd是一个开源的分布式键值对存储系统,专门为集群之间提供可靠的共享数据服务。
Etcd运行在每一个etcd集群的中央服务机器上(不用担心,随后我们会详细讲述此处),可以兼容机器运行的失败,甚至是中心机器运行失败(此时其他机器会替代中心机器)。
系统使用Raft一致性算法将数据的复制分发到etcd的节点。一致性是容错分布式系统的一个基本的要求,一致性也包含很多服务上的数据一致。这样一旦系统得出结论,这就是最终的结论了。
Deis使用etcd来存储数据,Kubernates同样也在使用etcd存储数据。
优化etcd集群的大小
Etcd集群的推荐3个、5个或者7个成员。尽管更大的集群可以提供更好的容错能力,但是它的写操作性能会不断降低,因为此时数据需要被复制到更多的机器上。常规上,集群中使用3或者5个成员就足够满足系统需求了。推荐集群中的成员数量是奇数个的,奇数个成员的集群不会更改大部分的需求数量,但可以通过增加额外的成员从而增加系统的容错能力。
下面的实践中我们对比一下偶数个成员和奇数个成员的不同:

正如表中描述,增加额外一个成员扩充集群的大小到奇数成员数量是值得的。
在网络分区中,集群奇数成员可以保证在网络分区结束后总还会有大部分可以操作的集群。
更多关于etcd的内容,请参考etcd的文档说明。
下面是一个中央服务器的etcd设置:
#cloud-config coreos: etcd2: # generate a new token for each unique cluster from https://discovery.etcd.io/new discovery: https://discovery.etcd.io/60887e46255f4efew37077ccf12b5f06a54a initial-advertise-peer-urls: http://$private_ipv4:2380 # listen on both the official ports and the legacy ports # legacy ports can be omitted if your application doesn't depend on them listen-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001 listen-peer-urls: http://$private_ipv4:2380,http://$private_ipv4:7001 data-dir: /var/lib/etcd2https://discovery.etcd.io/new?size=3 已经定义使用,因此在初始化etcd是必须满足是3个成员的集群。
代理模式
当你为提供一个中央服务而启动一个隔离的etcd集群,worker机器就需要连接到etcd集群,并把自己作为一个集群成员注册进去,这样就可以接收部署集群 fleet units,获取操作系统的更新等等。
运行在每一个工作节点最容易的方式是通过代理,而不是启动etcd本地服务。运行etcd作为代理允许你网络上的etcd容易被发现,因为它可以作为本机服务运行在每一台机器上。在这个模式下,etcd作为一个反向代理主动向etcd节点发送客户端请求。由于etcd代理不能参与etcd的一致性复制,所以它既增加了还原力,也不减少集群的写操作。
需要通信的etcd服务可以连接到本机。
Etcd目前支持两种代理模式:readwrite和readonly。
默认的代理模式是readwrite,可以提供对集群的读写请求操作。
通过集群成员列表,代理可以周期性的轮转到每个成员,这样可以表面将所有的流量转发给一个成员。
下面是一个设置代理的例子:
#cloud-config coreos: etcd2: listen-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001 advertise-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001 discovery: https://discovery.etcd.io/60887e46255f4efew37077ccf12b5f06a54a proxy: on通过下面URL,这些经由本地的客户端连接访问etcd中央服务:
https://discovery.etcd.io/60887e46255f4efew37077ccf12b5f06a54a关于更多etcd代理的介绍可以参考文档。
集群架构
根据集群的大小和集群的使用场景,下面有几条共同的集群架构准则是必须遵守的。
我们强烈建议设置固定数量的机器运行etcd中央集群服务,再分离出一个单独固定数量的机器专门用于分布式应用控制,例如Deis,kubernetes,Mesos,OpenStack等。
分离出这些服务到固定数量的机器,可以确保它们能跨数据中心和可用区域分配,设置的静态网络允许简单启动。
如果你担心依赖发现服务,这种设计可以消除你的后顾之忧。
然后就可以设置你的worker机器连接到中央服务。在这种设置中,你可以放大或者缩小你的机器从而满足你的需求,再也不用担心超多集群的额定人数。
想获得通过cloud-config文件配置设计不同集群的架构的更多信息,请参考文档。
下面我们一起看几个例子:
笔记本上的Docker开发环境
如果你在本地开发,但是计划在生产环境运行容器,本地环境将帮助你获取镜像。
在本地笔记本上很容易就可以运行Docker命令,从而操作VMware或者VituralBox中的CoreOS VM。
下面是一个CoreOS VM开发环境:

一个容易开发测试的集群
下面的CoreOS集群开发测试被充分利用:

这种设置对运行你的开发环境,测试环境,裸机环境或者云虚拟主机都十分有用。
如果你是第一次使用CoreOS,你会经常调整你的cloud-config文件,需要启动,重启甚至重装好多机器。
这样不用通过生成新的发现URL和重启etcd,很容易就可以开启一个etcd节点。通过这种方式,你就可以根据你的需求从etcd节点自由地引导更多的机器。
fleet、locksmith、和 etcdctl的所有功能照常工作,但是通过etcd代理连接集群,而不是使用本地etcd实例。因为etcd只通过代理模式访问所有的机器,你的CPU和RAM会减少一些压力。
现在设置的这种环境具有最佳的性能。
一个CoreOS生产集群分为中央服务部分和worker部分:
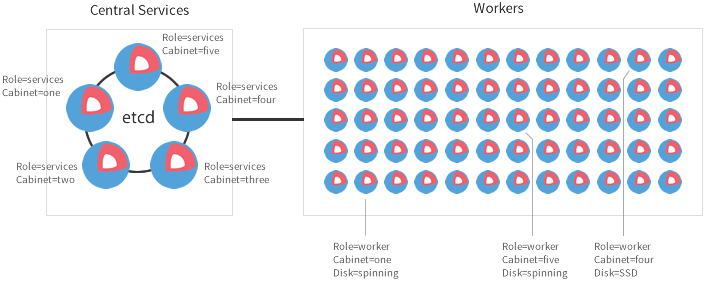
将集群划分为中央服务和worker利于生产环境。对于大的集群,我们推荐要有三到四台机器运行中央服务。这样设置完成后,就可以在worker部门增加任意多的机器完成任务。每一个worker机器通过本地etcd代理使用在中央机器的分布式etcd集群。Fleet通过使用机器元数据和全局fleet units引导中央服务和worker机器上的jobs。我们将在下一篇文章中叙述这些。
注意:如果你有Deis,Kubernetes,或者需要专门机器的其他服务,不要把这些服务放到etcd集群机器中。相反专门使用固定数量的机器完成。我们推荐使用etcd集群奇迹运行其他任何etcd服务。
总结
这篇文章中我们讲到:
- Cloud-config配置文件
- 为什么建议etcd集群的机器数量为奇数
- 代理模式运行etcd
- 一些etcd集群的常规设置
在下一篇文章中我们就会更详细地学习一下sytemd和fleet
