论坛1 | 数据时代的技术与应用 项亮 「分布式机器学习」
-
时间: 2016年7月28日
发言人: 瓜子二手车首席科学家 项亮
演讲主题: 分布式机器学习
最近人工智能很火,我的主要研究方向,从上学以来都是研究机器学习的,所以我今天就跟大家分享下分布式机器学习。考虑到今天大部分听众不是做机器学习的,所以我今天讲的是机器学习中只跟工程相关的一部分,所有跟数学、算法相关的都没有讲,同时会介绍和云的关系。

今天首先介绍一下机器学习最简单的算法;二是三个机器学习的分布式框架;三是最新的机器学习的部署方式,比如谷歌目前所有的机器学习的部署方式。
首先说说机器学习的简单算法。机器学习有很多算法,最简单的就是Naive Bayes,其算法跟实现WordCount的难度是一样的。剩下的机器学习算法分两个学派,一个是频率学派,另一个是贝叶斯学派。这两个学派,随着这两年深度学习的发展,频率学派就翻身了,在深度学习之前,都是贝叶斯学派。

举最简单的例子,Logistic Regression是频率学派的东西,但其实贝叶斯学派也在Logistic Regression也有各种推导。这里提出了分布式机器学习最简单的模型,整个Logistic Regression最核心的就是下面这几行代码。首先我需要有一个模型,就是全局的内存;然后是数据,每次读一行或几行数据,根据中间的优化算法,由读出的数据更新一下全局的模型。然后先在局部算一下这次要更新多少,再在全局上把整个模型更新一下。这涉及到三个组成部分,一个是数据,一般是存在磁盘上;第二个是优化,实际上就是进程,要用到CPU的计算的部分;第三个是模型,为了效率,基本都放在内存里。整个过程就是优化程序,CPU需要从硬盘上读数据,然后更新内存。

这中间涉及到两种类型的并行化。一种是数据并行化。刚刚我说的计算模型,就是CPU从硬盘上读数据,然后更新内存,都在一台机器上,大家平时写程序大部分都是在做这种事情。第一个问题就是如果一台机器的磁盘存不下所有的数据,这是大数据遇到的第一个问题。这个时候一般就会用分布式文件系统去存储数据。所以算法需要支持从分布式文件系统上读程序,做数据并行化。
还有一个是模型并行化,这是在数据并行化之后会遇到这个问题,一般公司不太会遇到。模型并行化是指模型大到一台机器存不下。比如在广告点击率预估的算法里用的大部分模型都是TB级别的,所以一般来说一台机器是存不下的,就要涉及到用分布式缓存去存储模型。
接下来讲讲当数据太大、模型太大时,过去几年常用的三种解决方案。第一个就是MapReduce。我说的都是最经典的模型,不包括Spark出现之后改造的新模型。在经典模型里,MapReduce只能解决数据并行化的问题。怎么做数据并行化呢?首先Map进程类似前面所说的优化的程序,在你不知道的很多台机器上启动,每个程序都是无状态,也就是这些Map进程不需要知道其他的Map进程究竟在哪台机器上,不需要服务发现。然后,Map进程启动的时候会给出数据分片,也就是数据并行化中的一小块数据。Map进程需要在自己的数据分片上训练自己的模型,需要在自己的内存里维护一个模型。有的时候也不一定在内存里维护,模型会把本地模型变化reduce出去。最后通过在硬盘之上把所有reduce出来的模型变化进行合并。机器学习都是迭代的算法,需要在下一个模型把reduce模型分发给各个进程再进行迭代。这里有个问题,如果一个模型太大,一个Map进程存不下,怎么办?没有办法,因为在MapReduce的计算框架下是没有办法做到的。
MapReduce的问题,第一是整个模型的reduce是要等到所有Map结束后才能进行。Map进程的速度取决于最慢的Map,在我们以前的经验里,如果有几千个Map,最慢的Map是非常慢的。其次在Map和Reduce的过程中,在Reduce整个模型的过程中是靠磁盘的,速度比较慢,以前用MapReduce写程序最大的痛苦就是I/O。第三个问题每次迭代及需要启动大量的Map任务,Hadoop的任务启动是秒级的过程,特别慢的将近1分钟也是有可能的。Map读数据也是从磁盘上读,读模型也是从磁盘上读,整个计算过程涉及到大量的磁盘I/O。不过Spark出来后,很多磁盘I/O问题都消除了,这里说的是传统的MapReduce模型。
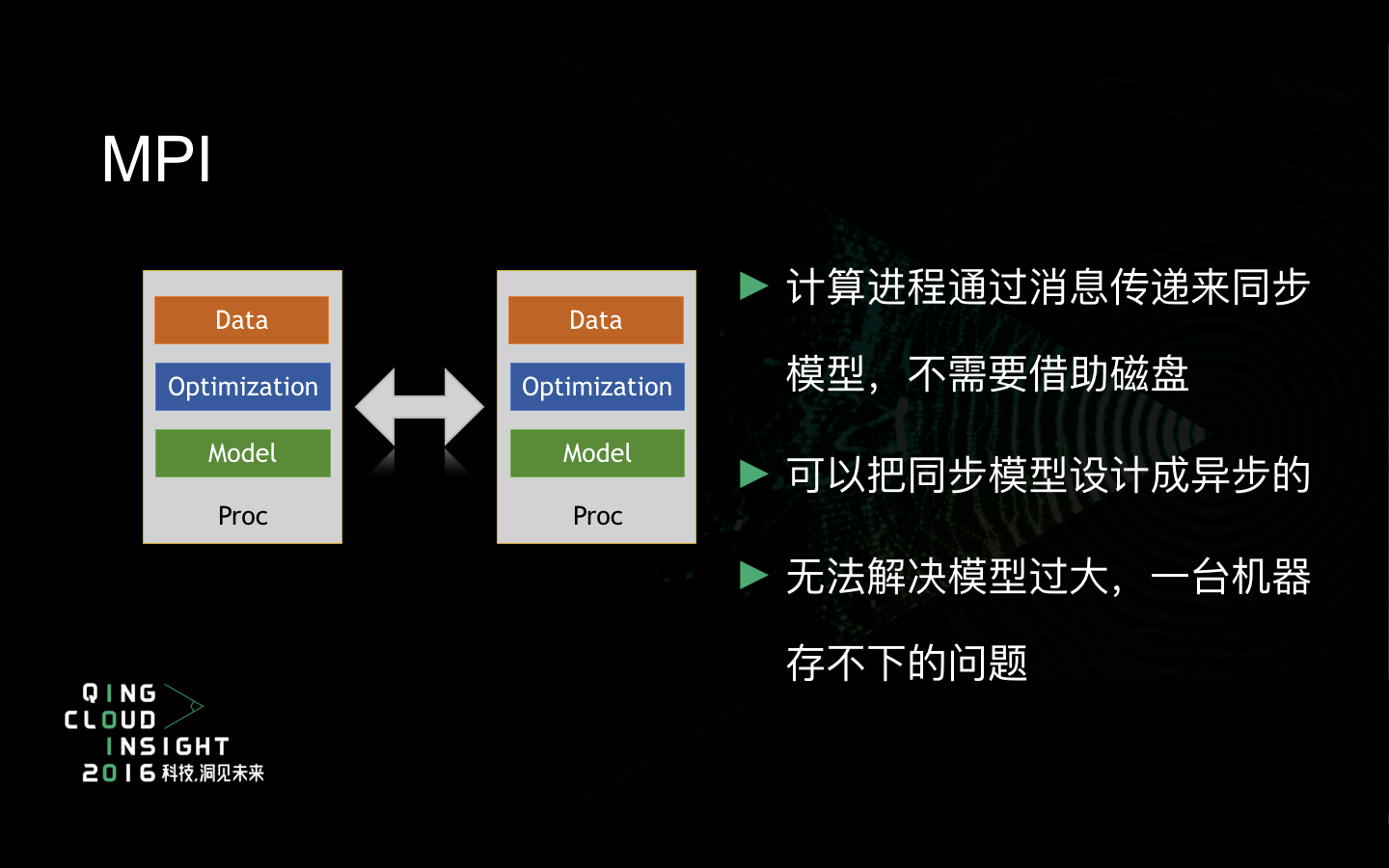
接下来说MPI。MPI跟MapReduce有一个最大的区别。模型其实是一块内存,关键的问题是这个内存是一个共享的分布式内存,还是单独本地内存。传统的MPI是每台机器有自己的内存。五年前淘宝做分布式的Logistic Regression的时候用的是单独的内存,要保证每台机器可以存下整个模型,所以它的每台机器的内存都是几百G的。它有一个好处是不需要像MapReduce一样reduce模型,既不需要通过磁盘I/O来Reduce模型,也不需要在训练完一轮以后再reduce模型。因为它是通过消息传递来同步模型,在训练的过程中可以随时reduce模型,就是把所有的本地变动让所有人都知道,都更新到自己的本地模型里去。所以MPI的更新模型和训练模型可以设置成异步的。而MapReduce中,Map就是训练,reduce就是更新模型,必须先map再reduce。但MPI同样没有办法解决模型太大,一台机器存不下的问题。

大概在四年前左右,Google用Parameter Server解决深度学习,用来识别猫脸。这样的做法其实是很简单的,用分布式的缓存取代每台机器的内存。最简单的是前面说的部分如果没有reduce的过程,而是换成分布式的缓存,每台机器凡是涉及到模型变动的就跟分布式缓存进行交互。但最早用Memcached和Redis做分布式缓存的时候都会涉及到性能问题。当时我们在Hadoop上试验时,一涉及到本地的内存里找不到,需要hit分布式缓存时,并且分布式缓存不是自己实现的,就是用Memcached和Redis做缓存的时候,性能都是几个数量级的下降,并且圈定的过程非常慢。
Parameter Server就是要设计一个专门用来为机器学习服务的分布式缓存,而不能是用现成的Memcached。其实用现存的Memcached最早是Yahoo提出来的,后来发现这需要专门设计。跟MPI不一样,MPI是任意两台机器都可以互相通信。在Parameter Server里,机器之间是不需要通信的,只需要和Parameter Server进行通信。好处是在于,服务发现只需要让所有机器知道Parameter Server在哪里就可以,不需要让所有机器知道各自互相在哪儿。
其次,Parameter Server是一个专门为机器学习设计的分布式缓存,它本身是需要高可用的。大概的流程就是每台机器训练的时候都是从Parameter Server拿到当前样本需要的参数,这个参数不会特别大。因为当前的样本量可能就是1万条或者是10万条,不会涉及到特别大的模型。拿到这个模型以后会计算出这一部分参数更新的diff,再把diff发回到Parameter Server,由Parameter Server本身来Merge。

Tensorflow和Mxnet是中国人开发的深度学习框架,基本上都是通过Parameter Server实现多机多卡的训练。因为Tensorflow的Parameter Server并没有公开,我只举Mxnet的例子。比如说它用的是ps-lite的parameter server,和Redis的差不多,用一个server用来存储参数,用worker来训练,实际上worker是一个应用端的程序,它会通过Scheduler知道server在哪儿。Scheduler有两个功能,第一个是服务发现,意思是通过它才能知道server在哪。第二个它还可以控制同步,这里的同步主要是机器学习所需要的。比如我有10个worker都在在训练,如果有一个worker训练特别快,会对最终的模型精度造成影响,Scheduler会让这个worker等一等。

最后说一说部署平台。我特意在青云上把整个Mxnet搭了一遍。我算是一个青云的个人用户,我习惯每当研究一个新的框架时,就会在青云上搭一遍,搭完以后再删掉。搭完以后,性能测得差不多了,我就会在公司的机器上再部署一遍。
部署平台现在最流行的有两个,一个就是Yarn,另外一个是Mesos。Yarn比较适合离线训练,不适合长时服务。其次是无迭代,统计类的算法,这其实就是最早的MapReduce算法,适合于你的整个训练过程,就和WordCount一样。比如协同过滤和Naïve Bayes这两个算法基本上跟WordCount一样。因为Yarn没有提供原生的服务发现功能,在Yarn里要支持Parameter Server机器学习分布式算法的实现就有一定困难。Mxnet也有Spark的版本,这个Spark版本是怎么实现的呢?因为ps-lite通过Scheduler实现了服务发现,不过这里的问题就是谁来发现Scheduler在哪儿,才能知道其他服务在哪。如果在Yarn里也要启动Scheduler,有必须要有服务发现。最早的实现方法是单独找一台机器启动Scheduler,再在配置文件中告诉所有进程它在某个IP的相应端口。但基于云的方法,最好是把他们都能在云上启动起来。
第二种部署平台是Mesos,我特地在青云上搭了一套,用DCOS来做,它的好处是同时支持离线训练和在线训练。新的机器学习的算法都要求支持online learning。以前大部分机器学习的做法就是把今天零点之前的所有日志都扒出来,训练一个模型并把模型上线,今天一天都用这个模型。比如像“今日头条”这种新闻推荐,在昨天的数据里压根儿就没有这些东西,怎么办?比如广告也是,如果今天出了大量新的广告,在昨天的模型里没有,这都是问题。现在最新的机器学习训练方面是用online learning,训练样本是根据打点的日志,日志一来,就立即在线进行训练,整个训练的程序是需要长时的服务程序。当然,最简单的做法就是长时的服务和离线程序写两套不同的系统,两套分开部署。但是写程序的都知道只要是写两套程序,这两套程序就是很难运行出同样的结果。我们希望整个训练框架同时支持离线训练和在线训练,所以在Mesos的基础上会更容易。
第二,我们希望支持服务发现,要支持Parameter Server就必须得提供服务发现的功能。因为Parameter Server本身就是全局的。
第三,因为现在整个深度学习的计算过程整个基于梯度的算法,都是可以通过Parameter Server实现的。现在整个深度学习的算法基本上是在Mesos上进行并行化。

最后一个是Docker,我觉得机器学习用Docker是非常好的事情。做过机器学习的人都知道,比如做语音识别、图像识别都需要装大量的库,而且这个库只有这个任务才用得到的。另外库还会有一个问题,比如我依赖一个库,它是比较旧的版本,没办法跟最新的程序吻合。因为机器学习的依赖库非常多,开发机器学习的程序人员大部分都是不怎么会写程序的,他们得依赖大量的程序。而依赖的版本会冲突,用Docker解决依赖的问题是比较好的。
第二个支持Mesos。唯一需要担心的就是网络性能。我刚刚的描述里,整个Parameter Server里最大的问题就是全局分布式的缓存,所有机器跟它通信的时候,网络性能会有很大的问题。我自己都是用host的网络模式进行测试,不知道其他网络模式的性能是否会有下降。
我今天介绍了整个分布式机器学习的基础知识,谢谢大家。
