论坛1 | 数据时代的技术与应用 苑明理 「彩云天气的实时大数据流分析与处理」
-
时间: 2016年7月28日
发言人: 彩云天气CTO 苑明理
主题: 彩云天气的实时大数据流分析与处理
谢谢。刚才大家听到的部分技术氛围比较浓厚,我想给大家换换风格。我给大家讲一些故事。

大家看到的这幅图是在下雨,这是一幅描绘下雨的画。虽然2B、2C我们都做,但我们最出名的一款产品是叫“彩云天气”的APP,它跟下雨密切相关。
这次我会从3个方面进行分享:也许大家对彩云天气并不是非常熟悉,所以我会给大家介绍彩云的商业创新在哪里,我们选取了怎样的技术路线,以及我们是怎样把技术路线落实在产品架构中。我会更宏观的介绍彩云天气的实践。
中国会有《新闻联播》这样的节目,每天7点正式开始,讲很多国家大事。在结尾会有《天气预报》,这个节目收视率很高的。大家有没有想过为什么《天气预报》会跟新闻这样的节目密切联系在一起?现在要讲的就是媒体变革和天气预报之间的关系。

我们先从这幅画讲起。如果了解科学史的话,大家会知道这幅画表现的是一次著名的旅行,小猎犬号带着达尔文环游了世界,达尔文在一座岛上想明白了进化论。我要给大家讲的是小猎犬号的舰长,因为一次海难深深的触动了他,他决定在英国沿岸部署观测站,这是英国第一次建立起观测网络。利用电报把这些数据传到后来的英国国家气象局的前身。他把这些数据汇总起来用一定方法分析天气变化,并供风暴报警。比较重要的一次事件是在1861年,他发布了世界上第一个天气预报。

天气预报开始出现的时候就跟媒体有深切的联系,这个联系不是偶然的。人们在上个世纪30年代就开始尝试用电视为媒介进行天气预报的播送。世界上第一个天气预报员是乔治·考林,他在电视上对着一张地图进行讲解,这种形式在上个世纪50年代就已经出现了。

无论是报纸,还是电视,这两种媒介都有一个特点,它都是一点对多点,在同一时间把同一个内容送达到多人,无法做到多对多,不能满足个性化的天气需求。气象上很早就可以进行高精度预报,但只能服务于领导人出行和卫星发射这样的工作,没有办法让它服务于大众。因为媒体的形式决定了它不可能投送个性化的天气预报。这说明天气预报和媒体间的深刻联系在发挥作用。

现在是移动时代,我们每个人当下所在的时间、空间都可以被手机捕捉到,手机也可以成为信息传递的渠道。这个时候就有条件向每个人投递高精度的天气预报。彩云天气目前正在实践这个工作,我们向公众提供新水平的服务。

除此,我们还有一些方法上的创新。这是彩云天气后台的运行图,每个图标就是一个用户回报当地的天气状况。比如我们看到东部地区在下雨,西部地区是晴的。
沿着时间轴的变化可以发现它跟雷达图显示的降雨带的对应关系是非常清晰的。从北到南有一场降雨的话,这个图标也会一直闪烁,雷达图的云带也同步过来。我们可以用众包的方式校准天气预报,拓展了传统的数据源。因为它可以补充很多不足,有的时候雷达宕机,或者是数据传递不及时,我们就可以通过这些数据来校准。
做过iOS开发的话的同学可能会知道前几个版本的iPhone已经可以收集气压数据。所以我们也可以做到通过各地的手机来采集气压数据,回传到彩云天气,进而帮助我们去分析风场等更有价值的信息。可以说,我们通过用手机用户反馈的方式众包了天气数据采集,让每个手机都变成观测站,而且是低成本的运行 。中国气象局目前在全国有几万个自动站,彩云天气在全国的手机用户有几百万,我们可以采集到更密集的数据,质量也很高。
在介绍完彩云天气的创新形式之后,我想向大家来介绍我们的技术路线。

大家提起天气预报和气象分析就会觉得是很高大上的部门,它的业务需要无数的超级计算机才能支撑起来。彩云天气目前只有不到15个工作人员,也没有那么多的钱去购买超级计算机。我们是怎么用这么少的资源来撬动这件事情的呢?技术上怎么解释呢?我来给大家做一个分析。
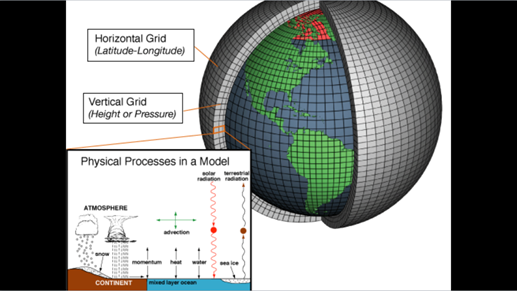
这是传统的天气预报处理方法,它会把地球上空间划分成球面网格,这些网格的精度可能是几十公里、几公里等。这种形式下数据量是三维展开的,是跟空间精细程度的立方是成正比的。

每分钟计算的格点数是面积乘以高度,得出三维的点数,大概可以估算出来,其数量在亿级别。只做中国的气象预报可能要算几亿个格点。时间精度是分钟级别或者是几分钟级别,要在一分钟或几分钟之内把几亿个格点上的状态全部计算出来,计算量是巨大的,不是一个小公司可以随便撬动的。面对这样的问题,解决的方法就是用超级计算机。

那么彩云天气是如何处理这个问题的呢?随着时代的发展,现在的观测手段是通过气象雷达。

现在大家看到的是气象雷达接收到的数据,有黄色、绿色、橙色的,橙色和黄色的部分代表雨比较大,绿色的是雨比较小,蓝色的是没有雨但是阴天。还可以看到一个“十”字,它是雷达的中心。雷达扫一圈大概需要6分钟。

在气象局的日常工作中,可以根据连续几帧的雷达图进行分析,图上的三帧分别是:8:41、8:47和8:53,。

大家可以看到这三张图显示的气象元素是移动的。气象局的工程师会根据移动的趋势大致得到一个地点的天气状况。如果我们分析一个地方是不是下雨,只考虑最主要的因素,其实可以不管模式计算的格点的状态,只需要考虑雷达图,把雷达图做最主要的因素。实际上人们就已经在这样做了。我们现在做的工作就是把这套思路自动化。

表面看来这个工作只是图形处理,但它的内在有一些有意思的地方。看前面的格点图,算一个点就需要知道周围的点,一个点依赖于周围的点,再算下一个格的时候又需要依赖它周围的点。我在计算未来的某一个时刻的天气变化的时候必须需要所有数据,只有一点的数据没有办法算出这一点将来某个时刻的数据,我得需要知道这个点周围十几个点的数据。
我们这种方法只需要知道两幅图之间的差异,分析出它的速度,就可以预测下面若干个阶段的天气变化,并不需要知道更多的东西。换句话说,我们现在的预报方法的是局部化的。那么这种做法会带来哪些变化呢?
首先,我们把问题从三维变成了二维,这已经降低了计算量,从几亿到几千万,但还不够。

对于表达式求值或者是函数求值,在计算科学中有一个概念,它有惰性求值和积极求值的区别。积极求值适合做批处理,惰性求值适合做响应式计算。传统气象模型的分析方法是一层依赖一层,没办法做简单的惰性求值,只能积极求值,必须整体全部计算完再输出结果,是批处理的方式。但是,从我们的角度,因为数据之间的关联性被取消掉了,我们是可以做惰性求值的,只是算一点,而不是算整体,意味着计算量成倍的下降,可以达到十万的级别,即一分钟只需计算十万个点。因为用户量大概就是每秒钟上千个用户的访问,只要每秒钟计算了这上千个点就可以解决问题。这背后有一套计算科学的原理来支撑着业务的发展和计算模型的采用。
最后,我们再聊下彩云天气的技术和架构的话题。从大的方面来讲,我们就是一个数据公司,都是标准的数据处理方法和流程,有爬虫、外部数据接口、实时数据采集。

数据进来以后,我们会进行数据清洗。数据清洗的意义非常重大,否则后面的工作都无法进行。数据清洗之后得到基础数据,按照一定的时间送到数据服务层。数据服务将多个数据层上的数据汇总起来投递给用户。这是数据的简单流向,从采集到最后的输出。同时,还有模型的训练,采集到数据之后要训练机器学习的模型。这个模型会回馈给数据清洗和数据服务。
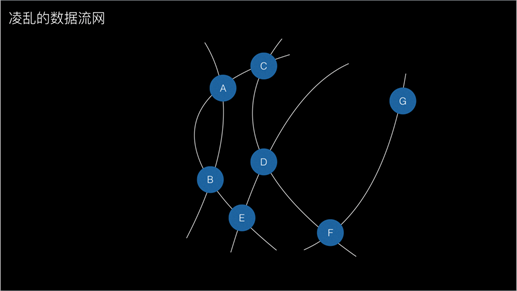
大家看到这个流程是很清晰的,我们在发展的时候也会经历不同阶段。开始是非常清晰的图画,后来就演变成这样零乱的,一台机器跑一个任务,另外一台跑另外一个任务,它们之间有依赖关系,数据流从一个节点流到另一个节点,变成不可管理的状态。这大概是我们一年半之前的状态。
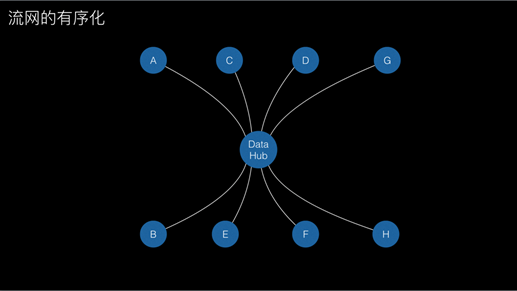
一年前我们做了一次讨论,最后就形成了这样的方案。我们有一个中心的数据节点,数据被统一管理起来,流动就变成请求数据结点。这个版本是目前线上的,我们现在又往前走了一步。这个版本遇到的问题就是中间数据节点可能变成瓶颈。
我们正在考虑的是采用一个分布式的文件系统。目前正在考虑采用的是一个用Go语言写的、叫做Seaweed的分布式文件系统,它是仿照Facebook的Haystack,我们感觉比较轻量,又很有意思。刚才讲的是文件的管理。那么数据的流动,我们是想用事件机制的方式来做,这个版本正在开发过程中。

我们其实也踩了很多坑。现在我们每一个雷达每6分钟会有数据更新,全国有几百个雷达站,必须得能够近实时更新数据。一旦雷达站发现有新的数据进来,必须得在1分钟以内更新(现在我们可以做到十几秒以内更新到数据库中,对外提供服务)。这个业务要求我们必须编写一个高效的数据服务:数据处理必须快,数据加载必须快,编程模型必须简单。这个问题如何解决呢?

为了这个结果,我们走过很多弯路,最后发现:数据处理最快的数据结构是数组,加载速度最快的数据结构还是数组,编程最简单的数据结构也是数组。换句话说,可以在数组的基础上设计数据服务的设施。

我们最后选择的就是mmap这个很古老的技术。我们的编程语言用的是Python这样的脚本语言。脚本语言通常情况下很难做到进程间共享数据。我们发现有一种方法就是在古老的mmap的技术上,把Python的内存数据块共享出来。科学计算在Python平台上有一个很好的工具叫做NumPy。可以使用mmap这种技术,把一个大数组抽象到外存里去。这个时候就可以提供很好的数据服务。这个技术既简单,又管用。我们做插值服务、人工神经元网络预测、解算微分方程,全部可以用这个方法来解决。

我们可以做到神经网络的计算单机QPS 1000多,插值计算可以达到4000多,一次访问只需要4个毫秒就解决了。我们之前用过一些时髦的技术,但是感觉还是回归到古老的技术比较好用。回归到数组是非常有意思的事情。可能下面还会沿着数组的方向再想想,我们还能不能做一些更有意思的工作。比如,时空数据的分析工具,我们可能会自己开发。
我今天跟大家分享的主要就是这些内容。谢谢大家!
