论坛4 | 多维共生的云生态 张辉 「功能联盟篇——创新网络构建高效云计算平台」
-
时间: 2016年7月28日
发言人: Mellanox亚太区解决方案营销总监 张辉
主题: 功能联盟篇——创新网络构建高效云计算平台
大家好,我叫张辉,来自Mellanox,负责亚太区的解决方案的推广、商务合作以及技术推广。Mellanox这家公司稍后会有一个介绍。
我不是帮青云做广告,但是我看到这个以后要有一些解读。每个人都有自己的解读,我本身做技术出身,但我一直做大客户,要研究用户。所以青云是我的合作伙伴,也是我的用户,所以我要研究我的客户。首先,我本身也是做marketing,一眼看过去,酷暑季节,有冰棍有西瓜,有10%的降价。整个这个布局和文案做的不错。我会对我的marketing提了一些要求,简单明了,然后应景。第二个解读,第六次公有云资费下调,说明黄总(黄允松)一个重要的战略是进攻公有云。第三个解读,为什么敢降价?一定是成本有极大的优化。怎么优化成本?其实在底层X86的硬件价格竞争已尽很激烈,我不认为硬件厂商会突然间将成本降低十几个点让利给青云。我相信一定是青云的技术创新导致它的效率更高。在上午的演讲中,我记得甘泉甘总提到,他对CPU利用率和网络利用率很满意。网络利用率已经到80%,我相信CPU也会很高,唯一不满意的是硬盘。所以我相信一定是技术创新导致我有资本敢于降价,有理解错的大家指正。Mellanox是在纳斯达克上市的以色列公司。以色列是传奇的地方,种种传说我就不赘述了。Mellanox在全球2500多人,中国区就六十多人。我们的业务是提供端到端的互联,即服务器和存储之间通过以太网或InfiniBand等方式,实现端到端互联。我们的优势就是低延迟、高性能、高吞吐。这家公司比较小众,Mellanox公司和其他传统公司不太一样,它是从芯片开始做,做到网卡adapter,到以太网价换机和InfiniBand交换机,到软件和服务,为高性能计算,web2.0,数据中心,包括云存储,提供高性能连接,提高整体的传输效率。今天的题目是创新网络构建高效的云计算平台,跟大家分享一下我们大概做了哪些点。
网络很重要,不言而喻。我想通过一个段子来讲网络的重要性。这是我给地下听众的的第一个问题。大家知道制约中国互联网未来十年发展最大的瓶颈是什么?对,是互联网通络。昨天晚上一场大雨,我在上地,很多朋友纷纷晒说打车打到80多,甚至100多,因为后厂村那条让人抓狂的路导致的。网络也一样,你计算能力很强,存储能力很强,但互相之间通讯没法通信或通信能力很低,就像万恶的互联网通路一样,有点风吹草动就歇菜了。我过去的从业经历一直在存储凌云,在做存储过程中,发现传输效率高低决定了存储效率。Mellanox会从三点支持高效网络。第一点对虚拟化的支持;另外一点是加速的,加速这边可以做InifiBand的RDMA和RoCE;还有融合,是指网络,存储和计算的融合。这是三个方面,后面会有一些解读。今天因为时间关系,不会特别详细。
Mellanox对虚拟化的支持。在上午听甘泉甘总提到了效率问题,因为虚拟化有它的好处和坏处,你在享受虚拟化便利的同时你必须要接受虚拟化带来的损耗。那怎么办,只能忍。上午我听甘总讲他会有一个Container Instance的方案,来跳过虚拟层跳过Hypevisor。 那么SR-IOV一样,会跳过Hypervisor这一层,让你的效率更高。还有通过网卡,内置的eSwitch,提高效率。在RDMA这里,会支持三层路由(RoCEv2),包括基于硬件的拥塞控制。包括在最流行的Overlay的支持,也就是数据包从封装开始和解封装,及与VXLAN的的无状态卸载。还有一些基于隧道协议的无状态卸载的支持。具体的技术细节会因为应用和业务场景的不同儿有差异会采,但基本上这些点是云计算能够用到的特别实用的点。
提到云不得不提OpenStack,是现在比较火的,也是市场云平台管理的领导者。它本身有一套完整的开源架构支持网络管理。Mellanox已经是整个基于这套架构,我们提供很多端到端的方案,和OpenStack 的service集成。像Nova,Cinder, Neutron 都有很好的集成。在最新的Havana版本的openstack里,对我们InfiniBand和以太网卡已经有很好的支持。以为这在Havana版本的openstack里,已经可以使用我们10G,40G,甚至FDR 56G的infiniBand网络。这些架构使用可以使整个Cinder的存储效率也有很大的提升。包括网卡内嵌式的交换机可以让你的访问性能以Baremetal的性能访问。以裸机的形式访问,你有多少性能我完全使用多少性能,这是特别好的特点。当然,因为有不同的发行版本,那么针对比较主流的Openstack发行版我们都做了相应的功能验证和测试。所有这点告诉大家部署OpenStack,我们都有很好的支撑,大家可以放心部署。这是与OpenStack有很好的集成。
RDMA,那我的第二个问题就是有人知道RDMA什么意思吗?中文英文都可以。
听众:直接内存访问协议,
算你答对,没错。这个协议出来很久了,有一段时间了。但是最近开始火起来了,原因在什么地方?我是做存储的,很多人即便不做存储也有感觉,传统存储延迟是6-10毫秒,主要来自三个方面:磁盘介质,软件层面,再有就是网络层面。在传统架构里,磁盘介质几本上占主要成分。以SAS盘为例,基本上是6毫秒左右。然后软件层大概会是200微秒,这就差一个数量级。到网络传输层是100微秒左右。这两年,无论是个人电脑,亦或是企业应用,实际上SSD都在普及,包括NOLE。上午甘总说青云会用全部SSD,占大头介质的问题就解决了,因为SSD的延迟只有几十微秒。反正到了软件层面,大家一直觉得软件不成问题的时候,反而成了问题。那么软件的问题在哪,在TCP/IP的堆栈这里。你有中断,你有几次握手,就意味着你的延迟少不了。你想用这套,你就要忍受200微秒的延迟。另外,随着网络芯片和网络技术的发展,网络延迟也由以前的100微秒降到几十微秒。这样综合来看,200微秒的软件(TCP/IP)延迟就尤为突出。解决矛盾要解决主要矛盾,哪也就是解决TCP/IP的问题。TCP/IP我个人认为相当长一段时间恐怕无法改变,那么只能绕过去。那么RDMA(Remote Direct Memory Access),也就是远程直接内存访问。这样的结果是,我的CPU直接访问网卡地址,完全跳过TCP/IP堆栈,那么这个延迟就更好了,网络延迟加上介质延迟只有几十个微秒。所以为什么会有RDMA。这里有一组数据,一个是用了RDMA,一个是没有用。RDMA有4VMs,8VMs,16VMs,使用iSCISi的有8VMs和16VMs。我们会发现不使用RDMA的时候,只能跑不到1GB,使用RDMA之后基本上能跑到6GB,理论上还能更高,这里因为受CPU总线的限制。这就是为什么要用RDMA。除了系统提升,带宽差不多6倍以上提升,延迟降低了5倍。这里用我们最新的交换机你会更低,我们新的交换机基本上是200纳米级。CPU利用率也会降低。这块大家可以看到为什么用RDMA。为什么整个BAT都很认可RDMA技术,包括国外的Facebook,包括不便透露名字的告诉也好,其实能解决办法的就是这个。RDMA已经内置在组件里面了,不需要太多的周折,使用也比较广泛。
InfiniBand比较小众,一般一提到InfiniBand就会提到HPC(高性能计算),这两者是紧密相关的,代表低延迟高性能和高吞吐的一个极致。有人会问Openstack 里是否要用到这么极致的技术,我们也看到。一个例子,剑桥大学有一个生命研究室,他就用了基于InfiniBand的Openstack。他们之前是传统的HPC用户,已经习惯了高性能低延迟的环境。他要上云,为什么上云?传统的HPC已经解决不了如安全性、灵活性和信息共享的问题。所以只能上云。要想维持高性能,那么选择了基于InfiniBand的Openstack。上了以后效果极佳。第一期用了2240个核心,加上56G的InfiniBand。这个算是给大家抛砖引玉,一个思考。RDMA天然支持InfinBand。同样的,从Havana版本,Opestack也开始支持InfiniBand。同时像SR-IOV,MAC到GUID的映射,VLAN到pkey的映射,以及 SDN都可支持。当然这是一个相对小的市场,但也不能忽视。再一个是Ceph,基本上在Openstack上基本上都会用到Ceph。在存储领域里,其实比较难搞的就是网络。FC相对会好一些,但是涉及到以太网协议相关的各种协议,各种考量,各种安全性,还有流控,就相对比较复杂。大家知道现在在一个2U或者4U的服务器里可以装十几到几十块盘不等。以机械盘为例,存储的吞吐达到到1.5-2GB/S都不算很难的事情。如果换成SSD这个数值会翻倍,或翻基本。那么在网络这边,千兆的网卡肯定是不行了,也已经超了万兆网上限。如果还是这样的网络环境,节点计算能力很强,吞吐能力也很强,但我出不去,憋死了。憋死自己就算了,但我这是集群架构,节点的通信也通过网络来实现,但以为IO的吞吐,节点之间无法进行通信,我不知道这个节点什么状态,等不到消息就会默认节点就死了。那么假死节点越来越多,虽然分布式的好处是某一个节点两个节点死了,甚至上百个节点死了都没问题,但在这种网络里面,很有可能所有的节点都认为对方死了,整个分布式系统最开始设计的分布式问题会导致整个系统崩溃。所以,基于此未来要考虑达百G网络。大家大家应该都明白。 网络必须要通顺。这边有一个测试,千兆、万兆和4万兆的比较。
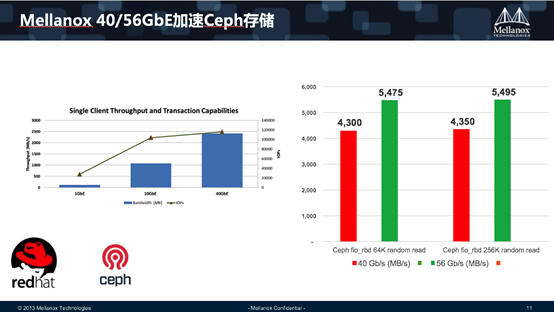
另外有一个数据,Mellanox有40GbE和56GbE。Mellanox是线性增长,也就是所见即所得。淘宝上的买家秀和卖家秀千差万别,有的买家秀卖家说求你了,把它删了吧,因为差的太远了。Mellanox可以做到我说什么就是什么。大家可以看右边这两个柱子,分别是在40G和56G不同情况环境下,一个是64K的块,一个是256K的块。在不同的测试环境下。大家可以看到一个相当稳定的数值。这带来一个信息,使用Mellanox,你需要考虑的是你的应用层怎么部署,你不需要考虑我的网络。我的网络从始至终,从最小的到最大的都没问题。所以这里是我们对产品给的一个承诺,整个的性能稳定性是有保障的。

再是CloudX。今天的主题是X Partners,刚好我们这个架构是CloudX。CloudX把所有Mellanox的技术特点,加上业内Openstack,融合在一起的参考架构。他包括有存储,应用的加速,包括网络管理,自动化,以及基于硬件的安全,包括硬件隔离,等等一系列东西。大家都知道,部署云是件挺复杂的事。不管是公有云还是私有云,首先要有之前细致严格的评估,然后软件硬件的集成,可用性的评估,弹性的评估,到最后要考虑性能,效率和成本怎么平衡。造成的结果是上云过程很愿望美好,但很难上。第一位嘉宾分享了五步,这还是在生态圈里在做。如果对一个普通的用户,难度和挑战会更大。国内上云用户失败很多,或者不承认自己失败。只上了第一层上了虚拟化就说我上了云,其实他离云还很远。CloudX就是提供一个架构,会让用户部署云的风险和时间缩小一些。这只是提供一个架构,借助我们整体业内优秀的服务器存储以及青云这样的服务商,一起来实现的。这是CloudX的基本架构。
CloudX这个架构里面我们支持的还比较广泛。从云Hypervisor层面,比如说Openstack,VMware,包括Microsoft Azure都支持。同时应用层面,Oracle、MongoDB, MySQL,包括Cep。从多终端访问来讲,包括传统的PC, 笔记本、Pad,各种智能手机都支持,这个在做云这是必须要支持。 我刚才反复提性能问题,效率问题,这里有几个例子和大家分享.有Hadoop的,有mongoDB的。以Hadoop为例,这是我们实测例子。1TB处理100个文件,经过CloudX,性能会有很大提升。同样的,mongoDB,这边有4M操作,有2倍的提升。底下的Redis基本上是几倍的提升。给大家一个基本的感觉,整个架构你的性能基本上都是翻倍的。
其实Cloudx这个技术从诞生那天开始它就在不断的成熟。上周前我接受采访的时候也问了一下,我们和青云是什么样的合作关系,和青云怎么合作,我觉得这是互相促进的过程。我们有我们自己的技术,但我们需要有人帮我们把它真正运用到云环境里。青云是我们最好的实践者和合作伙伴。他们用我们的产品,运用过程中发现你有的特点是很好,但有的特点和青云不一样,你能不能改,怎么改?这个特点是不是真的需要,真的需要,改了之后青云和我们说这个功能很好,还有其他的功能,这个过程中是我们互相帮助。在整个发展过程中和青云,我们自己的CloudX都在发展,提升的效果也越来越显著。未来支持平台也越来越多。这里有个数据,Cloud X将帮助IT成本降低50%,这没什么大不了,是真的可以做到。
最后给大家做一个分享。我想熟悉Openstack的人应该都知道Red Hat Enterprise Linux OpenStack这个版本。这个版本具有更好的性能,同时提供更可靠的Openstack架构,同时对大量的扩展,弹性等企业级用户的常见需求有更高的支持,包括提供内置的云安全功能。Mellanox通过了的这一版本认证。同时Mellanox Plugins可以提供最好的性能支持,而且对Neutron的本地集成做的和好。

刚才提了很多性能和效率的提升,最终还有一个问题,那就是钱的方面,成本有没有变化。我开篇提到了我的一个猜测,技术创新一定帮青云省了很大成本,青云才有这个魄力去降价。这里是我们测试的例子。可以看到,从效率,从性能都有很大提升。另外我们关注一点,成本的降低,有几个数据点成本降低都在30%以上。我不好猜测青云这次降了多少,但我估计也不会太低。这是投资回报率的问题,刚才嘉宾提到技术驱动型公司,或者销售驱动型公司,归根结底,能不能减下去。初期可以靠情怀,但如果公司要运转,大家毕竟要吃饭,第一个嘉宾提到车的问题,毕竟要车,毕竟要养老婆孩子,能不能赚钱,这是核心问题。云计算讲那么多,核心一点是帮我们节省成本,让我们资金使用率最大化,让ROI更高。Mellanox也同样关注怎么能帮助我的合作伙伴,帮助我的最终用户降低成本,提高它的投资回报率。这里都有相关体现。

最后是Azure的一个例子。使用RDMA,使得效率特别高。这个里可以看一下数据,在40G跑满的情况下,对CPU的利用率几乎没有,基本上是0点几的使用率。Intel现在把CPU越做越强,Intel就希望所有的应用或者动作都经过CPU。那么这实际上会产生一个物极必反的效果。对CPU过份依赖,它万一有问题怎么办,到最后反而CPU会成为瓶颈。包括今天下午黄总提到了英特尔税,你一旦上了英特尔船就下不来了。我今天最后一个问题:联想也好,浪潮也好,曙光也好,这些只要是以CPU为主,或者是PC server为主的,或者是笔记本的,帮谁打工?都是帮英特尔、三星,希捷打工。这些组件的成本基本上都控制在人家手里。你能做的非常有限,能做的无非是高效管理高效运作。传统IT这块做不了太多东西,所以现在传统IT厂商拼命做解决方案,只用才有机会做一些value-added,才会有利润可挣。这是我自己这么多年的体会。所有的鸡蛋放在一个篮子的结果势必是这个篮子哪天有所失的话基本上就废了。同样,应用各有所长,该有CPU来做的由CPU来做,该由网络来做的工作网络来做,可以由网卡来做,可以交换机来做,我也提到了RDMA,会使网卡效率更高,你的CPU效率更高。举一个例子,青云买一台机器,24个Core,网络消耗了8个Core,那只能卖16个Core出去。如果使用RDMA,我不需要CPU来处理网络的workload,24个core都可以卖了。这只是小小的例子。
最后,CloudX应用范围很广,无论是国家安全大数据运算,包括医疗健康,以及生命科学高密度计算,以及智能交通,都有比较大的应用场景。今天主要是给大家抛砖引玉,因为我们毕竟涉及几层架构的东西,希望通过这个分享认识大家。另外,希望未来有合作的机会,能了解Mellanox,这是我们公众微信号,大家可以扫描加入,关注我们Mellanox,以后多交流,共同进步。
谢谢各位,谢谢主办方青云。
