论坛5 | We. Developers. 孙敏 「Unified Search Solution」
-
时间: 2016年7月28日
发言人: 孙敏|VMware R&D Staff Engineer
主题: Unified Search Solution
大家好!
首先特别感谢大家能坐在这里,能跟大家交流,也让我班门弄斧。我先介绍一下,我们部门的主要任务是帮助客户解决问题,针对客户报过来的问题,我们从VMware的角度给他们提供一个解决方案。
我今天给大家解决的是Unified search。我们都知道现在其实人工智能和机器学习都特别的热门,刚才我在旁边的会场听一个讲座,那关于数据时代的技术和应用,当时他的出品人王啸先生说了一段话让我印象特别深刻,他说现在我们的Alpha Go和人竞争的时候,我们还有能力和它进行一争上下,但是将来当事情发展到一定程度的时候,我们根本没有可能战胜这样一个非常智能的机器人。
同时他还讲到,我们任何一个智能化的数据分析都有一定的边界。当我听到这两句话的时候兴奋,因为我今天讲的和王啸先生说的不谋而合,我们要用我们的人工智能和机器学习解决问题,我们的边界是只关注用户报的已经出现的问题。所以我的边际其实是很小的,并不是很大,我只是针对特定的东西解决特定的问题。
既然提到了我们要解决客户的问题,我就不得不提我们公司的客户支持模式。其实VMware和很多公司一样,我们花了很多精力和成本在解决客户的问题,客户报过来的问题对我们来说意义是非常重大的,我们也非常关注他们的满意度。所以在我们公司内部事实上实行了三层的客户支持模式。第一层是我们会有很多的现场工程师,他们实际驻扎在各个客户的现场,帮助他们去构建他们的虚拟化设备。如果说你这个公司有这样的需求,你需要做一个虚拟化的项目,我们的现场工程师可以帮你做一个规划,规划完了以后我们会帮你做实施和运行。如果出现了任何问题,我们现场第一时间帮你解决。
接着我们有第二层,并不是所有的客户都有现场工程师的指导,因为出于成本的限制。有一些大的客户,他们可能愿意花一些金钱或者是愿意花一些时间购买这样的服务,但是对于中小企业而言,如果没有购买这样的服务怎么办?事实上他们可以把很多问题反馈给我们,他们可以打电话甚至可以通过电子邮件,或者是在一个论坛上吐槽发文章,我们都可以把这些信息收集过来进行反馈,这个信息会收集给客户支持团队。这个团队主要的功能和职责:是我收集到客户所有的信息,我从这些信息当中进行提取,我看看这些信息是不是可以第一时间解决掉,如果我可以解决的话我可以马上给你反馈和方案。
当然很多问题并不是现场工程师或者是客户支持很快可以解决的,那些问题需要我们R&D团队的参与。所以在这种情况下我们会从R&D的角度去权衡和分析这些问题,看看这些问题是不是值得我们去研究。
经过这样层层的过滤和筛选,我们最终的目的是把所有客户的问题全部都解决掉。所以在实际的生产过程当中是这样的,如果用户他发现了一个问题,那么他就可能通过现场工程师,也可能通过打电话的方式,把这些问题反馈给我们的JSS Team,如果用户发现问题了,我们可以第一时间反应用户发现场景是什么样的,它的配置是什么样的,他当时发现问题的时候系统日志是什么样的。我们把所有的问题收集起来进行相应的分析,分析完了以后我们想这些问题是不是可以修正的,如果可以修正的话我们是不是可以在下一个版本当中把这样一个Feature进行更新。于是这样一层一层,我们把所有我们认为可以解决的问题,通过这样一些方案把它解决掉。
说到第三个题目就是我们这些问题的类型,其实有一类问题是所有人可以关注到的,就是这类问题发生的概率并不是很大,它很小。但是它的影响程度非常大,它对客户业务的影响也非常大,它始终处于所有人关注的焦点,因为一旦这个问题出现的话,有可能影响到下一个单子的合同。对于这类合同,我们内部其实花了很多的时间和精力解决它,所以这里我不想把太多的时间和精力花在那些问题上,那些问题已经有足够的团队解决它。我现在想看到是另外一类问题,也许被我们平时所忽略的问题,那些问题是什么样的呢?就是当客户把一个问题报过来以后,我们经过研究发现,这个问题是已知的问题,而且这个已知的问题事实上已经有了解决方法,而且这些解决的方法我们已经通过一些KB,就是我们叫做Knowledge Base的文档已经公布出去了,我们随便在网上一搜就可以找到这些文档,这个时候我们在想,为什么这种已知的问题客户还会报过来呢?而且在现实的工作当中,我们会发现这些问题的数目还很大。因为它很大,所以它花掉了我们JSS Team,包括我们R&D的时间和精力很多。
我自己大概做了一个简单的估算,这类问题的占比比第一类问题的占比要成倍的增长,为什么看似一个非常简单的搜索过程,他要花掉那么多的时间和精力呢?事实上中间有很多原因可以理解,第一事实上用户在报问题的时候,他经常会对问题做一个简单的描述,然后他把这些描述反馈给我们,我们基于这些描述以及他们给我们的信息分析,往往客户给我们的一些描述和这个问题发生的根本原因并没有直接的关联关系。其实有很多这样的例子,用过VMware的产品大家知道,比如说出现了米国旗的问题,其实可能根本不是米国旗的问题,它可能是底层的网络。如果你通过误差的信息进行搜索的话,你得到的概率是非常小的。
其次,如果说客户给我们的信息事实上是非常准确的,但这个时候还会有一些问题,为什么?当那个问题反馈给我们JSS Team的时候,我们的搜索和解决问题事实上是半人工的,为什么是半人工呢?他给我很多描述,他跟我说他们的配置是什么样的,我们的工程师他的做法是这样,我把所有的东西拿过来看一下我从里面挑出来比较关键的,我们认为是Keywords的东西,我把这些东西拿出来和后台数据库进行匹配,如果匹配上我发现这个是已知的问题,就把解决方案反馈给客户。实际上这个人工搜索的过程,它有一定的风险,为什么?我们没有把握每一次,甚至每一个人都能准确的找到非常定位问题的Keywords。
同时,我们人才流失在这方面也有非常的影响,为什么?就是说一个非常资深的工程师,它的经验通过时间积累,是可以加大他的工作效率的,如果这样的工程师工作了五年,甚至是七年以后他离职了,然后你会发现他的经验和所积累的知识并没有在公司层面上进行积累和保留。所以我们的团队和我们这几个人会想,有没有一种方法可以帮助我们的公司,帮助我们的人能够解决这样一些问题。
于是我们想,我们要做一个智能的搜索引擎,它应该是什么样的呢?它应该向我们人的大脑一样,可以认知、识别、感知问题,它也可以进行自我学习,它通过自我学习不断修正后台已有的知识库,因为有了这样的知识库,因为有了这样一个智能的实施过程,它的搜索结果和匹配结果一定是非常有效的。
最后,我希望的是这个想法并不是仅仅停留在我们解决客户的问题上,它给我们带来的不单单是解决了客户已经发生的问题,它给我们带来的应该是我们的工作模式,以及我们未来的获取知识方式的改变。
我今天想讲的东西就这四个词,一个是智能,一个是自学习,一个是非常有效,最后是能给我们带来工作模式以及我们Knowledge Query的革新。
简单看起来,它是什么样子呢?现在我们手里有很多的信息,其中对于我们开发者而言,也许最熟悉的就是我们的源代码,源代码你可以挖出来很多东西。最直接的是什么呢?我们发现所有的LOG都来自于源码,任何时候出现的问题都是在源码里面出现的Print。还有一类就是KB,刚才我提到Knowledge Base,对VMware公司而言,我们发现已知的问题,这个已知的问题我们写成一篇KB的文档,发布在公网上,所有人都可以看到,实际上这是已在的知识库,只不过我们怎么样更好的运用知识库,在海量的知识库当中找到就是那一篇可以解决实际的问题。
最后是Bugzilla,Bugzilla是我们内部跟踪BUG的系统,这里面可能会有客户报过来的问题,它把所有的问题进行记录,其实这里面有很多很丰富的信息是关联的。还有一条是SR,SR事实上是我们的客户直接报给我们的问题,所有购买VMware产品的客户,他都有权限,也有ID向我们开SR,SR可以对问题进行描述,把他认为所有的信息传输给我们。我们说里有这么多信息,我们把这些信息拿过来之后,我们把它进行Training,我们要建立一个对问题描述的模型,这个模型直接反应出来问题是什么,以及它解决的方法。
当这个模型建立好之后,如果用户一旦发现任何的问题,它可以通过各种方式进行反馈,比如说电子邮件,比如说今天我手上不太方便,没有网络,我直接拿起手机拍照或者是说我直接录一段语音,或者我把系统当中所有的LOG抓出来打个包给你,或者我觉得VMware的产品太难用了,为什么从5.5升级到6.0有那么多问题,为什么CPU 64和32的时候会出错呢?我们会把所有的信息进行抓取,我们在已经建立好的模型库里面进行搜索,当然这个模型库应不是静态的,它是不停完善的,它有自学习的能力,每一次用户的反馈都可以修正我们模型的结果。
经过这样一个结果我可以给你准确的反馈出来Match的KB,我会从中分析你给我的问题是不是已经存在的问题,如果是一个已经存在的问题,我们有没有已经解决的方法,如果有我给你,如果没有你可以按照原来的方式继续进行解决问题的过程。比如说可以让我们VMware的同事进一步介入。
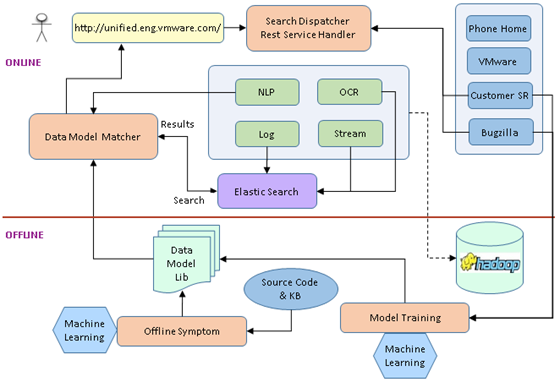
这一张图是我们大的系统架构,事实上在得到这张图之前,我们有很多其他的设计,最后我们选择了它,我们把这个系统分为ONLINE和OFFLINE架构,我不会详细给大家介绍所有的数据流。线上的部分是我接受用户的输入,当用户有任何问题的时候,你可以把信息填写进去。同时线上的部分可以给用户一个反馈,反馈的结果就是我的KP数。OFFLINE是最核心的部分,它体现了两块,一块是数据模型初始化的过程,把所有的信息收集起来,我要进行处理我有一个初始化模型库,有了这个模型库通过机器的自学习,通过用户的每次反馈,不停的修正这个知识库的准确率。有了这个基础之后,我们把用户的信息拿过来和我们模型库进行匹配,匹配完了之后我告诉你结果,大概就是这样一个流程。

这张图想给大家讲的是它的数据流,我们到底是怎么建立的,大家可能很奇怪。你有了这些东西你到底是怎么建立起来数据流的呢?我们先拿到源码,比如说我自己是做R&D的,我有足够的权限可以访问到我们公司所有产品的源代码,这是VMware给所有工程师最大的福利。因为我知道有很多公司他限制了你访问其他Repo的权限,你只能访问看到你自己写的那部分代码,你看不到别人的,但是在VMware我觉得这一点做的特别好,也是我们这个项目能够做下去的前提和根本。就是能我看到所有人写的代码。有了这些作为基础,才是我们后面工作的基础。我把所有的文件拿过来之后做一个扫描,扫描完了以后我提取我的Source Code里面所有和LOG相关的内容,以及它的函数名相关的信息拿出来。
我得到的是这些LOG的片断,以及所有的方法名,我为什么提起这两个东西呢?因为我们发现在系统当中,通常大家打印的系统日志都是带了方法名和一点一点LOG,其中还会有一些噪音。比如说我们的时间戳或者是其他的,但是我不管那些噪音,我只把这些有用的信息提取出来,我把它提取出来之后,这个时候我要用到已有已经发布的解决方法。那些KB里面包含了什么信息呢?通常情况下,对于一篇KB而言,他首先需要对用户发生了什么,有什么问题做一个简单的描述,有了这个描述之后他通常会说,如果你发现下面这些LOG,或者你发现系统出了这样的问题,它可能在什么地方存在什么BUG,它有可能在什么地方你可能配置的不对,这个时候他会告诉你接下来麻烦你做下面几步,做下面几步之后你这个问题就可能解决了。我们把KB拿过来创建一个Index,其实说实话我们这个名字叫做Unified Search,但是我们实现的并不是搜索引擎,我只是说用到这个搜索我把这个拿过来,我用的是Elasticsearch,我把它做成一个Search,Search完了最后的结果是我KB的LOG和我Source Code的LOG,它是有一个对应关系的。我把这个对应关系拿过来,把它作为我模型库的初始模型。当然这个初始的模型对于解决问题来说,还是太简单了。因为事实上你拿到的那些Keywords,你有可能发现有很多的冗余信息,它对我们唯一定位问题是没有太大帮助的,接下来我们怎么办。
有了这些问题之后,我们还有其他的信息,我们客户报过来很多SR,SR是有系统的,它是有历史积累的,每一个SR报过来我们有实时的记录,我们JSS Team做了什么,R&D的同事做了什么,最后的问题到底是怎么解决的,它是不是以KB的方式发出去了,所有的信息都是有记录的。而且这些信息是VMware从诞生到现在都有的,我们还有我们的BugZilla,BugZilla是我们内部总结所有问题的库,它可以是用户的问题,也可以是内部人员发现所有的问题。对我们R&D来说可能是最详细的,它记录了问题为什么发生,建立这些东西我就把它作为我输入,我把它作为我调整这个模型的数据源。
有了这些东西之后,我的模型在不断的修正,而且这个修正过程是全部自动化的,不需要人为干预的,我们的算法在不停的自学习,不停的修正这个模型,使得这个模型更加智能。
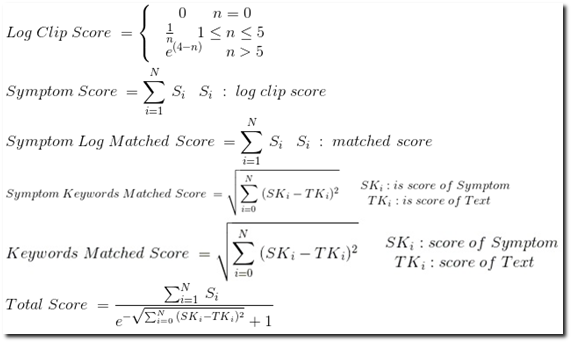
这张图其实就是背后最根本的算法,在这里我不会一一跟大家解释这个公式到底是什么含义。我想说的是这里面任何一个参数的更正会直接影响到我们最后的搜索结果,大家可能会问,你这个公式是怎么来的,你为什么要设计这样一个公式,这是我们最后实验的结果。其实我们四五个同事他们做了很多实验,他们不断的修正如果是这样的结果,我最后的命中率是不是有改变。所以我们经过很长时间的摸索和实践之后发现,这样一个公式目前对我们来说是目前达到最好的效果。
简单来说,我在最开始的时候有一个初始化的过程,我们会默认变更一个LOG片断,它都有职责,有可能是对应一个已知存在的问题。但是这个特征它会有权限,有些LOG它能唯一的问题,有些LOG太常见了,这些LOG其实并不是那么直接的可以定位到问题是什么。我们所做的就是在初始化的阶段,我们给每一个LOG一个特征值,给它一个特征打分。但是后面这个值是需要慢慢调整的,它通过自学习的过程之后,分数值不断的变化和修正,我可以让它返回给客户。当这个问题出现了,我可以认为如果它出现它有百分之多少的概率,就有可能有另外一个问题出现。
当然有了所有的打分系统之后,他可以判断出来这是一个问题吗?如果是一个问题这个KB能够解决它的概率是多少,有了这样一个工作之后,我们可以接下来做其他的工作。
接下来我们看一下效果怎么样,我们在实践当中搜索VMware的两个项目的Source Code,同时我们通过爬虫把所有的KB都爬下来。我们创建了大概1.6万个问题描述的模型。接着我们做的是随机的从BUG里面拿出两千多个,我看看这两千多个到底能不能返回正确的结果,结果是这样的。

也就是我返回的第一篇KB直接命中已知问题的概率是16%,头三篇的命中率是24%。大家可能会觉得这个数据看起来并不是那么好看,这个命中率看起来是很低的,其实这里面有很多原因,第一个是Source Code的扫描我只做了两个产品。而VMware发布了那么多产品,我在随机抽取的时候抽取所有的产品,这意味着有很多PR我根本没有做任何的分析。
第二点是我们在进行分析的时候,有很多的PR,他是一种任务性质的。任务是什么呢?就是我告诉你我要做一件事,但是这个事里面并没有包含你解决这些问题。如果你在这个PR里面空空的只是说,请你给我创建一个VC,请你给我创建一个Data Center。它并没有给我们进行数据分析和问题分析的任何贡献,这一部分PR也是1500多个,如果把这些抛去以后这些数值是大大增加的。
在这里我想说的我们的搜索过程是逆向的搜索过程,传统是我的用户把问题报过来,我需要从这些问题里面进行信息的提取,我提取了这些信息,然后对已有的KB进行搜索,搜索完了以后匹配给你结果。现在我们做的是反过来做,我们并不是说把用户的信息进行提取,而是我们把所有的,我刚才创建好的那些模型库去匹配用户的东西。
基于这个有好几个好处,一个好处就是我所常见的这些原型,它是已知,我们把已知的东西到未知的东西匹配,它的命中率会大大提高。第二点是它的效率会非常好,为什么?因为我们的模型库虽然说它是在不停的自我进行演变,它虽然可以增加。但是它的数量级别是相对稳定的,你把一个数量相对稳定的东西去匹配数量变化的东西,那么它的效率会增加的。尤其是在云计算当中,大家都知道在云计算当中客户的LOG可能是海量级的增长,你在海量级的LOG当中去提取信息,同时进行匹配,比起你反过来做,效率是大大降低的,为什么会这样呢?我们可以做一个非常简单的数学公式。
假设我们的模型库个数是M,我们的用户它的系统里面的数目是N,这个时候传统的方式,它的算法就是N×LOG M,当M变成相对固定值的时候,我们传统的方式就是N的量级。现在我反过来就是LOG N的差别,所以它的效率会大大增加。最好的一点就是,我们从客户的角度来看,这种方式是最简单的,甚至有点简单粗暴的意思,为什么呢?就是我们的用户在用这个东西的时候,我根本就不需要关心系统发生了什么,我不用看到底是哪个LOG,我到底应该发送哪部分信息,我把系统里面所有的LOG都抓出来,我打个包给你,这对用户来说是最简单易行的方法。甚至当他描述以后,我们不需要管到底是什么问题,我们直接复制扔到我们的系统里面自动进行分析,在这种模式下你给我的信息越多,我搜索出来越准确。
为什么?因为我们是反向的过程,我已经把有些已知的存在了,我拿这些东西到未知海量的信息当中进行匹配,这个时候你给我的信息越多,它越匹配。我进行搜索和提取的过程是很快的,所以这种反向的过程大大提高了系统的效率。
接下来我要讲的是我们做了那么多工作,到底能给我们带来什么。其实我特别想给大家分享一个数据,当然这个数据是我自己粗算的结果。我们做的这个事大概可以给我们公司每年省下几百万美金,当然大家可能会觉得奇怪。而且我也觉得这个数可能不准,因为我不是做财务的,我不是做市场的,我只是做了大概的估算。如果它给我们省下几百万美金每年的话,我觉得是可以很高兴的。但是至少可以给大家一点启示,这个事情值得我们花时间去做,它解决的并不是成本上的降低,它会给我们带来工作模式的变化。
就像我刚才第一页讲到的,现在我们的工作模式分三层,有了它以后我们完全可以分为四层,这好比说我有一个智能机器人,它24小时站在旁边随时待命解决客户的问题,客户有任何问题,我把所有的信息抓过来进行扫描,看一看这是我们出现的问题吗?如果是我马上给你结果。而且这个过程是全自动化的,用户不需要任何的干预,这是对我们目前工作模式的改进,而且我觉得自动化、智能化是将来重要的方向。
第二个是我们把所有的分析,其实你可以把它理解成是一种知识,这种知识给我们客户的方式现在还存在很多缺陷。我常常有这种感觉,知识在那里,但是我们没有用,知识在那里,但是我们没有发现。但是现在有了这样一些技术和想法,我们真的可以改变现在知识提供给客户的方式。如果你需要某种知识,你只需要给我一个请求,我就可以反馈给你。
我不知道大家是不是用过VMware vSphere,它经常会有一些问题,如果有一些问题,假设我们这个系统已经移植到vClient上,我可以实时的抓取vClient的状态,我分析它的状态,分析完了之后我告诉用户,你这个系统当中可能有这些问题,而且这些问题的解决方法是这样的,你需要吗?如果有的话,事实上它实现的机制和原理就是只要你有这样的需求,你给我一个请求,我就可以给你反馈一个知识和结果。我觉得这一方面也许是我们将来可以做,甚至是可以提高用户满意度的方法。
最后一项是这种方法其实并没有任何的限制,我觉得对任何一个软件产品,只要你知道源代码,它没有任何的限制。如果说这个东西能够集成到VMware的产品当中去,我相信它的前景应该是非常好的。在这里想说的是,这是我们四到五个员工四天之内写出来的,它其实是我们公司内部的一个软件比赛项目。我们有这样一个想法已经很长时间了,当时正好有这样一个比赛,我们有这样的契机把它实现了。所以从我自己的角度来说,如果四五个小伙伴,在四五天的时间能够给公司每年带来几百万的价值,我觉得还是很高兴的事,也希望这个想法能够给大家一点启发,谢谢大家。
